I very, very nearly didn t make it to DebConf this year, I had a bad cold/flu for a few days before I left, and after a negative covid-19 test just minutes before my flight, I decided to take the plunge and travel.
This is just everything in chronological order, more or less, it s the only way I could write it.
DebCamp
I planned to spend DebCamp working on various issues. Very few of them actually got done, I spent the first few days in bed further recovering, took a covid-19 test when I arrived and after I felt better, and both were negative, so not sure what exactly was wrong with me, but between that and catching up with other Debian duties, I couldn t make any progress on catching up on the packaging work I wanted to do. I ll still post what I intended here, I ll try to take a few days to focus on these some time next month:
Calamares / Debian Live stuff:
#980209 installation fails at the install boot loader phase
#1021156 calamares-settings-debian: Confusing/generic program names
#681025 Put old themes in a new package named desktop-base-extra
#941642 desktop-base: split theme data files and desktop integrations in separate packages
The Egg theme that I want to develop for testing/unstable is based on Juliette Taka s Homeworld theme that was used for Bullseye. Egg, as in, something that hasn t quite hatched yet. Get it? (for #1038660)
Debian Social:
Set up Lemmy instance
I started setting up a Lemmy instance before DebCamp, and meant to finish it.
Migrate PeerTube to new server
We got a new physical server for our PeerTube instance, we should have more space for growth and it would help us fix the streaming feature on our platform.
Loopy:
I intended to get the loop for DebConf in good shape before I left, so that we can spend some time during DebCamp making some really nice content, unfortunately this went very tumbly, but at least we ended up with a loopy that kind of worked and wasn t too horrible. There s always another DebConf to try again, right?
So DebCamp as a usual DebCamp was pretty much a wash (fitting with all the rain we had?) for me, at least it gave me enough time to recover a bit for DebConf proper, and I had enough time left to catch up on some critical DPL duties and put together a few slides for the Bits from the DPL talk.
DebConf
Bits From the DPL
I had very, very little available time to prepare something for Bits fro the DPL, but I managed to put some slides together (available on my wiki page).
I mostly covered:
A very quick introduction of myself (I ve done this so many times, it feels redundant giving my history every time), and some introduction on what it is that the DPL does. I declared my intent not to run for DPL again, and the reasoning behind it, and a few bits of information for people who may intend to stand for DPL next year.
The sentiment out there for the Debian 12 release (which has been very positive). How we include firmware by default now, and that we re saying goodbye to architectures both GNU/KFreeBSD and mipsel.
Debian Day and the 30th birthday party celebrations from local groups all over the world (and a reminder about the Local Groups BoF later in the week).
I looked forward to Debian 13 (trixie!), and how we re gaining riscv64 as a release architecture, as well as loongarch64, and that plans seem to be forming to fix 2k38 in Debian, and hopefully largely by the time the Trixie release comes by.
I made some comments about Enterprise Linux as people refer to the RHEL eco-system these days, how really bizarre some aspects of it is (like the kernel maintenance), and that some big vendors are choosing to support systems outside of that eco-system now (like CPanel now supporting Ubuntu too). I closed with the quote below from Ian Murdock, and assured the audience that if they want to go out and make money with Debian, they are more than welcome too.
Job Fair
I walked through the hallway where the Job Fair was hosted, and enjoyed all the buzz. It s not always easy to get this right, but this year it was very active and energetic, I hope lots of people made some connections!
Cheese & Wine
Due to state laws and alcohol licenses, we couldn t consume alcohol from outside the state of Kerala in the common areas of the hotel (only in private rooms), so this wasn t quite as big or as fun as our usual C&W parties since we couldn t share as much from our individual countries and cultures, but we always knew that this was going to be the case for this DebConf, and it still ended up being alright.
Day Trip
I opted for the forest / waterfalls daytrip. It was really, really long with lots of time in the bus. I think our trip s organiser underestimated how long it would take between the points on the route (all in all it wasn t that far, but on a bus on a winding mountain road, it takes long). We left at 8:00 and only found our way back to the hotel around 23:30. Even though we arrived tired and hungry, we saw some beautiful scenery, animals and also met indigenous river people who talked about their struggles against being driven out of their place of living multiple times as government invests in new developments like dams and hydro power.
Photos available in the DebConf23 public git repository.
Losing a beloved Debian Developer during DebConf
To our collective devastation, not everyone made it back from their day trips. Abraham Raji was out to the kayak day trip, and while swimming, got caught by a whirlpool from a drainage system.
Even though all of us were properly exhausted and shocked in disbelief at this point, we had to stay up and make some tough decisions. Some initially felt that we had to cancel the rest of DebConf. We also had to figure out how to announce what happened asap both to the larger project and at DebConf in an official manner, while ensuring that due diligence took place and that the family is informed by the police first before making anything public.
We ended up cancelling all the talks for the following day, with an address from the DPL in the morning to explain what had happened. Of all the things I ve ever had to do as DPL, this was by far the hardest. The day after that, talks were also cancelled for the morning so that we could attend his funeral. Dozens of DebConf attendees headed out by bus to go pay their final respects, many wearing the t-shirts that Abraham had designed for DebConf.
A book of condolences was set up so that everyone who wished to could write a message on how they remembered him. The book will be kept by his family.
Today marks a week since his funeral, and I still feel very raw about it. And even though there was uncertainty whether DebConf should even continue after his death, in hindsight I m glad that everyone pushed forward. While we were all heart broken, it was also heart warming to see people care for each other in all of this. If anything, I think I needed more time at DebConf just to be in that warm aura of emotional support for just a bit longer. There are many people who I wanted to talk to who I barely even had a chance to see.
Abraham, or Abru as he was called by some people (which I like because bru in Afrikaans is like bro in English, not sure if that s what it implied locally too) enjoyed artistic pursuits, but he was also passionate about knowledge transfer. He ran classes at DebConf both last year and this year (and I think at other local events too) where he taught people packaging via a quick course that he put together. His enthusiasm for Debian was contagious, a few of the people who he was mentoring came up to me and told me that they were going to see it through and become a DD in honor of him. I can t even remember how I reacted to that, my brain was already so worn out and stitching that together with the tragedy of what happened while at DebConf was just too much for me.
I first met him in person last year in Kosovo, I already knew who he was, so I think we interacted during the online events the year before. He was just one of those people who showed so much promise, and I was curious to see what he d achieve in the future. Unfortunately, we was taken away from us too soon.
Poetry Evening
Later in the week we had the poetry evening. This was the first time I had the courage to recite something. I read Ithaka by C.P. Cavafy (translated by Edmund Keely). The first time I heard about this poem was in an interview with Julian Assange s wife, where she mentioned that he really loves this poem, and it caught my attention because I really like the Weezer song Return to Ithaka and always wondered what it was about, so needless to say, that was another rabbit hole at some point.
Group Photo
Our DebConf photographer organised another group photo for this event, links to high-res versions available on Aigar s website.
BoFs
I didn t attend nearly as many talks this DebConf as I would ve liked (fortunately I can catch up on video, should be released soon), but I did make it to a few BoFs.
In the Local Groups BoF, representatives from various local teams were present who introduced themselves and explained what they were doing. From memory (sorry if I left someone out), we had people from Belgium, Brazil, Taiwan and South Africa. We talked about types of events a local group could do (BSPs, Mini DC, sprints, Debian Day, etc. How to help local groups get started, booth kits for conferences, and setting up some form of calendar that lists important Debian events in a way that makes it easier for people to plan and co-ordinate. There s a mailing list for co-ordination of local groups, and the irc channel is #debian-localgroups on oftc.
If you got one of these Cheese & Wine bags from DebConf, that s from the South African local group!
In the Debian.net BoF, we discussed the Debian.net hosting service, where Debian pays for VMs hosted for projects by individual DDs on Debian.net. The idea is that we start some form of census that monitors the services, whether they re still in use, whether the system is up to date, whether someone still cares for it, etc. We had some discussion about where the lines of responsibility are drawn, and we can probably make things a little bit more clear in the documentation. We also want to offer more in terms of backups and monitoring (currently DDs do get 500GB from rsync.net that could be used for backups of their services though). The intention is also to deploy some form of configuration management for some essentials across the hosts. We should also look at getting some sponsored hosting for this.
In the Debian Social BoF, we discussed some services that need work / expansion. In particular, Matrix keeps growing at an increased rate as more users use it and more channels are bridged, so it will likely move to its own host with big disks soon. We might replace Pleroma with a fork called Akkoma, this will need some more home work and checking whether it s even feasible. Some services haven t really been used (like Writefreely and Plume), and it might be time to retire them. We might just have to help one or two users migrate some of their posts away if we do retire them. Mjolner seems to do a fine job at spam blocking, we haven t had any notable incidents yet. WordPress now has improved fediverse support, it s unclear whether it works on a multi-site instance yet, I ll test it at some point soon and report back. For upcoming services, we are implementing Lemmy and probably also Mobilizon. A request was made that we also look into Loomio.
More Information Overload
There s so much that happens at DebConf, it s tough to take it all in, and also, to find time to write about all of it, but I ll mention a few more things that are certainly worth of note.
During DebConf, we had some people from the Kite Linux team over. KITE supplies the ICT needs for the primary and secondary schools in the province of Kerala, where they all use Linux. They decided to switch all of these to Debian. There was an ad-hoc BoF where locals were listening and fielding questions that the Kite Linux team had. It was great seeing all the energy and enthusiasm behind this effort, I hope someone will properly blog about this!
I learned about the VGLUG Foundation, who are doing a tremendous job at promoting GNU/Linux in the country. They are also training up 50 people a year to be able to provide tech support for Debian.
I came across the booth for Mostly Harmless, they liberate old hardware by installing free firmware on there. It was nice seeing all the devices out there that could be liberated, and how it can breathe new life into old harware.
Some hopefully harmless soldering.
Overall, the community and their activities in India are very impressive, and I wish I had more time to get to know everyone better.
Food
Oh yes, one more thing. The food was great. I tasted more different kinds of curry than I ever did in my whole life up to this point. The lunch on banana leaves was interesting, and also learning how to eat this food properly by hand (thanks to the locals who insisted on teaching me!), it was a fruitful experience? This might catch on at home too less dishes to take care of!
Special thanks to the DebConf23 Team
I think this may have been one of the toughest DebConfs to organise yet, and I don t think many people outside of the DebConf team knows about all the challenges and adversity this team has faced in organising it. Even just getting to the previous DebConf in Kosovo was a long and tedious and somewhat risky process. Through it all, they were absolute pro s. Not once did I see them get angry or yell at each other, whenever a problem came up, they just dealt with it. They did a really stellar job and I did make a point of telling them on the last day that everyone appreciated all the work that they did.
Back to my nest
I bought Dax a ball back from India, he seems to have forgiven me for not taking him along.
I ll probably take a few days soon to focus a bit on my bugs and catch up on my original DebCamp goals. If you made it this far, thanks for reading! And thanks to everyone for being such fantastic people.
This post describes how to handle files that are used as assets by jobs and pipelines defined on a common gitlab-ci
repository when we include those definitions from a different project.
Problem descriptionWhen a .giltlab-ci.yml file includes files from a different
repository its contents are expanded and the resulting code is the same as the one generated when the included files
are local to the repository.
In fact, even when the remote files include other files everything works right, as they are also expanded (see the
description of how included files are merged
for a complete explanation), allowing us to organise the common repository as we want.
As an example, suppose that we have the following script on the assets/ folder of the common repository:
dumb.sh
#!/bin/shecho"The script arguments are: '$@'"
If we run the following job on the common repository:
But if we run the same job from a different project that includes the same job definition the output will be different:
/scripts-23-19051/step_script: eval: line 138: d./assets/dumb.sh: not found
The problem here is that we include and expand the YAML files, but if a script wants to use other files from the
common repository as an asset (configuration file, shell script, template, etc.), the execution fails if the files are
not available on the project that includes the remote job definition.
SolutionsWe can solve the issue using multiple approaches, I ll describe two of them:
Create files using scripts
Download files from the common repository
Create files using scriptsOne way to dodge the issue is to generate the non YAML files from scripts included on the pipelines using
HERE documents.
The problem with this approach is that we have to put the content of the files inside a script on a YAML file and if it
uses characters that can be replaced by the shell (remember, we are using HERE documents) we have to escape them (error
prone) or encode the whole file into base64 or something similar, making maintenance harder.
As an example, imagine that we want to use the dumb.sh script presented on the previous section and we want to call it
from the same PATH of the main project (on the examples we are using the same folder, in practice we can create a hidden
folder inside the project directory or use a PATH like /tmp/assets-$CI_JOB_ID to leave things outside the project
folder and make sure that there will be no collisions if two jobs are executed on the same place (i.e. when using a ssh
runner).
To create the file we will use hidden jobs to write our script
template and reference tags to add it to the
scripts when we want to use them.
Here we have a snippet that creates the file with cat:
Note that to make things work we ve added 6 spaces before the script code and escaped the dollar sign.
To do the same using base64 we replace the previous snippet by this:
Again, we have to indent the base64 version of the file using 6 spaces (all lines of the base64 output have to be
indented) and to make changes we have to decode and re-code the file manually, making it harder to maintain.
With either version we just need to add a !reference before using the script, if we add the call on the first lines of
the before_script we can use the downloaded file in the before_script, script or after_script sections of the
job without problems:
The output of a pipeline that uses this job will be the same as the one shown in the original example:
The script arguments are: 'ARG1 ARG2'
Download the files from the common repositoryAs we ve seen the previous solution works but is not ideal as it makes the files harder to read, maintain and use.
An alternative approach is to keep the assets on a directory of the common repository (in our examples we will name it
assets) and prepare a YAML file that declares some variables (i.e. the URL of the templates project and the PATH where
we want to download the files) and defines a script fragment to download the complete folder.
Once we have the YAML file we just need to include it and add a reference to the script fragment at the beginning of the
before_script of the jobs that use files from the assets directory and they will be available when needed.
The following file is an example of the YAML file we just mentioned:
bootstrap.yml
CI_TMPL_API_V4_URL: URL of the common project, in our case we are using the project ci-templates inside the
common group (note that the slash between the group and the project is escaped, that is needed to reference the
project by name, if we don t like that approach we can replace the url encoded path by the project id, i.e. we could
use a value like $ CI_API_V4_URL /projects/31)
CI_TMPL_ARCHIVE_URL: Base URL to use the gitlab API to download files from a repository, we will add the arguments
path and sha to select which sub path to download and from which commit, branch or tag (we will explain later why
we use the CI_TMPL_REF, for now just keep in mind that if it is not defined we will download the version of the
files available on the main branch when the job is executed).
CI_TMPL_ASSETS_DIR: Destination of the downloaded files.
And uses variables defined in other places:
CI_TMPL_READ_TOKEN: token that includes the read_api scope for the common project, we need it because the
tokens created by the CI/CD pipelines of other projects can t be used to access the api of the common one.We define the variable on the gitlab CI/CD variables section to be able to change it if needed (i.e. if it expires)
CI_TMPL_REF: branch or tag of the common repo from which to get the files (we need that to make sure we are using
the right version of the files, i.e. when testing we will use a branch and on production pipelines we can use fixed
tags to make sure that the assets don t change between executions unless we change the reference).We will set the value on the .gitlab-ci.yml file of the remote projects and will use the same reference when including
the files to make sure that everything is coherent.
This is an example YAML file that defines a pipeline with a job that uses the script from the common repository:
pipeline.yml
Where we use a YAML anchor to ensure that we use the same reference when including and when assigning the value to the
CI_TMPL_REF variable (as far as I know we have to pass the ref value explicitly to know which reference was used
when including the file, the anchor allows us to make sure that the value is always the same in both places).
The reference we use is quite important for the reproducibility of the jobs, if we don t use fixed tags or commit
hashes as references each time a job that downloads the files is executed we can get different versions of them.
For that reason is not a bad idea to create tags on our common repo and use them as reference on the projects or
branches that we want to behave as if their CI/CD configuration was local (if we point to a fixed version of the common
repo the way everything is going to work is almost the same as having the pipelines directly in our repo).
But while developing pipelines using branches as references is a really useful option; it allows us to re-run the jobs
that we want to test and they will download the latest versions of the asset files on the branch, speeding up the
testing process.
However keep in mind that the trick only works with the asset files, if we change a job or a pipeline on the YAML
files restarting the job is not enough to test the new version as the restart uses the same job created with the current
pipeline.
To try the updated jobs we have to create a new pipeline using a new action against the repository or executing the
pipeline manually.
ConclusionFor now I m using the second solution and as it is working well my guess is that I ll keep using that approach unless
giltab itself provides a better or simpler way of doing the same thing.
The status quo
Back in 2015, I bought an off-the-shelf NAS, a QNAP TS-453mini, to act as my file store and Plex server. I had previously owned a Synology box, and whilst I liked the Synology OS and experience, the hardware was underwhelming. I loaded up the successor QNAP with four 5TB drives in RAID10, and moved all my files over (after some initial DoA drive issues were handled).
QNAP TS-453mini product photo
That thing has been in service for about 8 years now, and it s been a mixed bag. It was definitely more powerful than the predecessor system, but it was clear that QNAP s OS was not up to the same standard as Synology s perhaps best exemplified by HappyGet 2 , the QNAP webapp for downloading videos from streaming services like YouTube, whose icon is a straight rip-off of StarCraft 2. On its own, meaningless but a bad omen for overall software quality
The logo for QNAP HappyGet 2 and Blizzard s StarCraft 2 side by side
Additionally, the embedded Celeron processor in the NAS turned out to be an issue for some cases. It turns out, when playing back videos with subtitles, most Plex clients do not support subtitles properly instead they rely on the Plex server doing JIT transcoding to bake the subtitles directly into the video stream. I discovered this with some Blu-Ray rips of Game of Thrones some episodes would play back fine on my smart TV, but episodes with subtitled Dothraki speech would play at only 2 or 3 frames per second.
The final straw was a ransomware attack, which went through all my data and locked every file below a 60MiB threshold. Practically all my music gone. A substantial collection of downloaded files, all gone. Some of these files had been carried around since my college days digital rarities, or at least digital detritus I felt a real sense of loss at having to replace. This episode was caused by a ransomware targeting specific vulnerabilities in the QNAP OS, not an error on my part.
So, I decided to start planning a replacement with:
A non-garbage OS, whilst still being a NAS-appliance type offering (not an off-the-shelf Linux server distro)
Full remote management capabilities
A small form factor comparable to off-the-shelf NAS
A powerful modern CPU capable of transcoding high resolution video
All flash storage, no spinning rust
At the time, no consumer NAS offered everything (The Asustor FS6712X exists now, but didn t when this project started), so I opted to go for a full DIY rather than an appliance not the first time I ve jumped between appliances and DIY for home storage.
Selecting the core of the system
There aren t many companies which will sell you a small motherboard with IPMI. Supermicro is a bust, so is Tyan. But ASRock Rack, the server division of third-tier motherboard vendor ASRock, delivers. Most of their boards aren t actually compliant Mini-ITX size, they re a proprietary Deep Mini-ITX with the regular screw holes, but 40mm of extra length (and a commensurately small list of compatible cases). But, thankfully, they do have a tiny selection of boards without the extra size, and I stumbled onto the X570D4I-2T, a board with an AMD AM4 socket and the mature X570 chipset. This board can use any AMD Ryzen chip (before the latest-gen Ryzen 7000 series); has built in dual 10 gigabit ethernet; IPMI; four (laptop-sized) RAM slots with full ECC support; one M.2 slot for NVMe SSD storage; a PCIe 16x slot (generally for graphics cards, but we live in a world of possibilities); and up to 8 SATA drives OR a couple more NVMe SSDs. It s astonishingly well featured, just a shame it costs about $450 compared to a good consumer-grade Mini ITX AM4 board costing less than half that.
I was so impressed with the offering, in fact, that I crowed about it on Mastodon and ended up securing ASRock another sale, with someone else looking into a very similar project to mine around the same timespan.
The next question was the CPU. An important feature of a system expected to run 24/7 is low power, and AM4 chips can consume as much as 130W under load, out of the box. At the other end, some models can require as little as 35W under load the OEM-only GE suffix chips, which are readily found for import on eBay. In their PRO variant, they also support ECC (all non-G Ryzen chips support ECC, but only Pro G chips do). The top of the range 8 core Ryzen 7 PRO 5750GE is prohibitively expensive, but the slightly weaker 6 core Ryzen 5 PRO 5650GE was affordable, and one arrived quickly from Hong Kong. Supplemented with a couple of cheap 16 GiB SODIMM sticks of DDR4 PC-3200 direct from Micron for under $50 a piece, that left only cooling as an unsolved problem to get a bootable test system.
The official support list for the X570D4I-2T only includes two rackmount coolers, both expensive and hard to source. The reason for such a small list is the non standard cooling layout of the board instead of an AM4 hole pattern with the standard plastic AM4 retaining clips, it has an Intel 115x hole pattern with a non-standard backplate (Intel 115x boards have no backplate, the stock Intel 115x cooler attaches to the holes with push pins). As such every single cooler compatibility list excludes this motherboard. However, the backplate is only secured with a mild glue with minimal pressure and a plastic prying tool it can be removed, giving compatibility with any 115x cooler (which is basically any CPU cooler for more than a decade). I picked an oversized low profile Thermalright AXP120-X67 hoping that its 120mm fan would cool the nearby MOSFETs and X570 chipset too.
Thermalright AXP120-X67, AMD Ryzen 5 PRO 5650GE, ASRock Rack X570D4I-2T, all assembled and running on a flat surface
Testing up to this point
Using a spare ATX power supply, I had enough of a system built to explore the IPMI and UEFI instances, and run MemTest86 to validate my progress. The memory test ran without a hitch and confirmed the ECC was working, although it also showed that the memory was only running at 2933 MT/s instead of the rated 3200 MT/s (a limit imposed by the motherboard, as higher speeds are considered overclocking). The IPMI interface isn t the best I ve ever used by a long shot, but it s minimum viable and allowed me to configure the basics and boot from media entirely via a Web browser.
Memtest86 showing test progress, taken from IPMI remote control window
One sad discovery, however, which I ve never seen documented before, on PCIe bifurcation.
With PCI Express, you have a number of lanes which are allocated in groups by the motherboard and CPU manufacturer. For Ryzen prior to Ryzen 7000, that s 16 lanes in one slot for the graphics card; 4 lanes in one M.2 connector for an SSD; then 4 lanes connecting the CPU to the chipset, which can offer whatever it likes for peripherals or extra lanes (bottlenecked by that shared 4x link to the CPU, if it comes down to it).
It s possible, with motherboard and CPU support, to split PCIe groups up for example an 8x slot could be split into two 4x slots (eg allowing two NVMe drives in an adapter card NVME drives these days all use 4x). However with a Cezanne Ryzen with integrated graphics, the 16x graphics card slot cannot be split into four 4x slots (ie used for for NVMe drives) the most bifurcation it allows is 8x4x4x, which is useless in a NAS.
Screenshot of PCIe 16x slot bifurcation options in UEFI settings, taken from IPMI remote control window
As such, I had to abandon any ideas of an all-NVMe NAS I was considering: the 16x slot split into four 4x, combined with two 4x connectors fed by the X570 chipset, to a total of 6 NVMe drives. 7.6TB U.2 enterprise disks are remarkably affordable (cheaper than consumer SATA 8TB drives), but alas, I was locked out by my 5650GE. Thankfully I found out before spending hundreds on a U.2 hot swap bay. The NVMe setup would be nearly 10x as fast as SATA SSDs, but at least the SATA SSD route would still outperform any spinning rust choice on the market (including the fastest 10K RPM SAS drives)
Containing the core
The next step was to pick a case and power supply. A lot of NAS cases require an SFX (rather than ATX) size supply, so I ordered a modular SX500 unit from Silverstone. Even if I ended up with a case requiring ATX, it s easy to turn an SFX power supply into ATX, and the worst result is you have less space taken up in your case, hardly the worst problem to have.
That said, on to picking a case. There s only one brand with any cachet making ITX NAS cases, Silverstone. They have three choices in an appropriate size: CS01-HS, CS280, and DS380. The problem is, these cases are all badly designed garbage. Take the CS280 as an example, the case with the most space for a CPU cooler. Here s how close together the hotswap bay (right) and power supply (left) are:
Internal image of Silverstone CS280 NAS build. Image stolen from ServeTheHome
With actual cables connected, the cable clearance problem is even worse:
Internal image of Silverstone CS280 NAS build. Image stolen from ServeTheHome
Remember, this is the best of the three cases for internal layout, the one with the least restriction on CPU cooler height. And it s garbage! Total hot garbage! I decided therefore to completely skip the NAS case market, and instead purchase a 5.25 -to-2.5 hot swap bay adapter from Icy Dock, and put it in an ITX gamer case with a 5.25 bay. This is no longer a served market 5.25 bays are extinct since nobody uses CD/DVD drives anymore. The ones on the market are really new old stock from 2014-2017: The Fractal Design Core 500, Cooler Master Elite 130, and Silverstone SUGO 14. Of the three, the Fractal is the best rated so I opted to get that one however it seems the global supply of new old stock fully dried up in the two weeks between me making a decision and placing an order leaving only the Silverstone case.
Icy Dock have a selection of 8-bay 2.5 SATA 5.25 hot swap chassis choices in their ToughArmor MB998 series. I opted for the ToughArmor MB998IP-B, to reduce cable clutter it requires only two SFF-8611-to-SF-8643 cables from the motherboard to serve all eight bays, which should make airflow less of a mess. The X570D4I-2T doesn t have any SATA ports on board, instead it has two SFF-8611 OCuLink ports, each supporting 4 PCI Express lanes OR 4 SATA connectors via a breakout cable. I had hoped to get the ToughArmor MB118VP-B and run six U.2 drives, but as I said, the PCIe bifurcation issue with Ryzen G chips meant I wouldn t be able to run all six bays successfully.
NAS build in Silverstone SUGO 14, mid build, panels removedSilverstone SUGO 14 from the front, with hot swap bay installed
Actual storage for the storage server
My concept for the system always involved a fast boot/cache drive in the motherboard s M.2 slot, non-redundant (just backups of the config if the worst were to happen) and separate storage drives somewhere between 3.8 and 8 TB each (somewhere from $200-$350). As a boot drive, I selected the Intel Optane SSD P1600X 58G, available for under $35 and rated for 228 years between failures (or 11,000 complete drive rewrite cycles).
So, on to the big expensive choice: storage drives. I narrowed it down to two contenders: new-old-stock Intel D3-S4510 3.84TB enterprise drives, at about $200, or Samsung 870 QVO 8TB consumer drives, at about $375. I did spend a long time agonizing over the specification differences, the ZFS usage reports, the expected lifetime endurance figures, but in reality, it came down to price $1600 of expensive drives vs $3200 of even more expensive drives. That s 27TB of usable capacity in RAID-Z1, or 23TB in RAID-Z2. For comparison, I m using about 5TB of the old NAS, so that s a LOT of overhead for expansion.
Storage SSD loaded into hot swap sled
Booting up
Bringing it all together is the OS. I wanted an appliance NAS OS rather than self-administering a Linux distribution, and after looking into the surrounding ecosystems, decided on TrueNAS Scale (the beta of the 2023 release, based on Debian 12).
TrueNAS Dashboard screenshot in browser window
I set up RAID-Z1, and with zero tuning (other than enabling auto-TRIM), got the following performance numbers:
Finally, the numbers reported on the old NAS with four 7200 RPM hard disks in RAID 10:
IOPS
Bandwidth
4k random writes
430
1.7 MiB/s
4k random reads
8006
32 MiB/s
Sequential writes
311 MiB/s
Sequential reads
566 MiB/s
Performance seems pretty OK. There s always going to be an overhead to RAID. I ll settle for the 45x improvement on random writes vs. its predecessor, and 4.5x improvement on random reads. The sequential write numbers are gonna be impacted by the size of the ZFS cache (50% of RAM, so 16 GiB), but the rest should be a reasonable indication of true performance.
It took me a little while to fully understand the TrueNAS permissions model, but I finally got Plex configured to access data from the same place as my SMB shares, which have anonymous read-only access or authenticated write access for myself and my wife, working fine via both Linux and Windows.
And that s it! I built a NAS. I intend to add some fans and more RAM, but that s the build. Total spent: about $3000, which sounds like an unreasonable amount, but it s actually less than a comparable Synology DiskStation DS1823xs+ which has 4 cores instead of 6, first-generation AMD Zen instead of Zen 3, 8 GiB RAM instead of 32 GiB, no hardware-accelerated video transcoding, etc. And it would have been a whole lot less fun!
The final system, powered up
(Also posted on PCPartPicker)
Utkarsh Gupta
did 12.25h (out of 0h assigned and 12.25h from previous period).
Evolution of the situation
In August, we have released 42 DLAs.
The month of August turned out to be a rather quiet month for the LTS team.
Three notable updates were to
bouncycastle,
openssl,
and zabbix.
In the case of bouncycastle a flaw allowed for the possibility of LDAP injection
and the openssl update corrected a resource exhaustion bug that could result in
a denial of service. Zabbix, while not widely used, was the subject of several
vulnerabilities which while not individually severe did combine to result in the
zabbix update being of particular note.
Apart from those, the LTS team continued the always ongoing work of triaging,
investigating, and fixing vulnerabilities, as well as making contributions to
the broader Debian and Free Software communities.
Thanks to our sponsors
Sponsors that joined recently are in bold.
September.
Looking at performance traces and analysing scheduling and other issues.
CPU Cache doesn't really play into effect until I figure out the scheduling issues. They don't collide.
Utkarsh Gupta
did 1.5h (out of 0h assigned and 13.75h from previous period), thus carrying over 12.25h to the next month.
Evolution of the situation
In July, we have released 35 DLAs.
LTS contributor Lee Garrett, has continued his hard work to prepare a testing
framework for Samba, that can now provision bootable VMs with little effort,
both for Debian and for Windows.
This work included the introduction of a new package to Debian,
rhsrvany, which
allows turning any Windows program or script into a Windows service. As the
Samba testing framework matures it will be possible to perform functional tests
which cannot be performed with other available test mechanisms and aspects of
this framework will be generalizable to other package ecosystems beyond Samba.
July included a notable security
update of bind9
by LTS contributor Chris Lamb.
This update addressed a potential denial of service attack in this critical
network infrastructure component.
Thanks to our sponsors
Sponsors that joined recently are in bold.
Manipur
Lot of news from Manipur. Seems the killings haven t stopped. In fact, there was a huge public rally in support of the rapists and murderers as reported by Imphal Free Press. The Ruling Govt. both at the Center and the State being BJP continuing to remain mum. Both the Internet shutdowns have been criticized and seems no effect on the Government. Their own MLA was attacked but they have chosen to also be silent about that. The opposition demanded that the PM come in both the houses and speak but he has chosen to remain silent. In that quite a few bills were passed without any discussions. If it was not for the viral videos nobody would have come to know of anything . Internet shutdowns impact women disproportionately as more videos of assaults show Of course, as shared before that gentleman has been arrested under Section 66A as I shared in the earlier blog post. In any case, in the last few years, this Government has chosen to pass most of its bills without any discussions. Some of the bills I will share below.
The attitude of this Govt. can be seen through this cartoon
The above picture shows the disqualified M.P. Rahul Gandhi because he had asked what is the relationship between Adani and Modi. The other is the Mr. Modi, the Prime Minister who refuses to enter and address the Parliament. Prem Panicker shares how we chillingly have come to this stage when even after rapes we are silent
Data Leakage
According to most BJP followers this is not a bug but a feature of this Government. Sucheta Dalal of Moneylife shared how the data leakage has been happening at the highest levels in the Government. The leakage is happening at the ministerial level because unless the minister or his subordinate passes a certain startup others cannot come to know. As shared in the article, while the official approval may take 3-4 days, within hours other entities start congratulating. That means they know that the person/s have been approved.While reading this story, the first thought that immediately crossed my mind was data theft and how easily that would have been done. There was a time when people would be shocked by articles such as above and demand action but sadly even if people know and want to do something they feel powerless to do anything
PAN Linking and Aadhar
Last month GOI made PAN Linking to Aadhar a thing. This goes against the judgement given by the honored Supreme Court in September 2018. Around the same time, Moneylife had reported on the issue on how the info. on Aadhar cards is available and that has its consequences. But to date nothing has happened except GOI shrugging. In the last month, 13 crore+ users of PAN including me affected by it I had tried to actually delink the two but none of the banks co-operated in the same Aadhar has actually number of downsides, most people know about the AEPS fraud that has been committed time and time again. I have shared in previous blog posts the issue with biometric data as well as master biometric data that can and is being used for fraud. GOI either ignorant or doesn t give a fig as to what happens to you, citizen of India. I could go on and on but it would result in nothing constructive so will stop now
IRCv3
I had been enthused when I heard about IRCV3. While it was founded in 2016, it sorta came on in its own in around 2020. I did try matrix or rather riot-web and went through number of names while finally setting on element. While I do have the latest build 1.11.36 element just hasn t been workable for me. It is too outsized, and occupies much more real estate than other IM s (Instant Messengers and I cannot correct size it like I do say for qbittorrent or any other app. I had filed couple of bugs on it but because it apparently only affects me, nothing happened afterwards But that is not the whole story at all.
Because of Debconf happening in India, and that too Kochi, I decided to try out other tools to see how IRC is doing. While the Debian wiki page shares a lot about IRC clients and is also helpful in sharing stats by popcounter ( popularity-contest, thanks to whoever did that), it did help me in trying two of the most popular clients. Pidgin and Hexchat, both of which have shared higher numbers. This might be simply due to the fact that both get downloaded when you install the desktop version or they might be popular in themselves, have no idea one way or the other. But still I wanted to see what sort of experience I could expect from both of them in 2023. One of the other things I noticed is that Pidgin is not a participating organization in ircv3 while hexchat is. Before venturing in, I also decided to take a look at oftc.net. Came to know that for sometime now, oftc has started using web verify. I didn t see much of a difference between hcaptcha and gcaptcha other than that the fact that they looked more like oil paintings rather than anything else. While I could easily figure the odd man out or odd men out to be more accurate, I wonder how a person with low or no vision would pass that ??? Also much of our world is pretty much contextual based, figuring who the odd one is or are could be tricky. I do not have answers to the above other than to say more work needs to be done by oftc in that area. I did get a link that I verified. But am getting ahead of the story. Another thing I understood that for some reason oftc is also not particpating in ircv3, have no clue why not :(I
Account Registration in Pidgin and Hexchat
This is the biggest pain point in both. I failed to register via either Pidgin or Hexchat. I couldn t find a way in either client to register my handle. I have had on/off relationships with IRC over the years, the biggest issue being IIRC is that if you stop using your handle for a month or two others can use it. IIRC, every couple of months or so, irc/oftc releases the dormant ones. Matrix/Vector has done quite a lot in that regard but that s a different thing altogether so for the moment will keep that aside.
So, how to register for the network. This is where webchat.oftc.net comes in. You get a quaint 1970 s IRC window (probably emulated) where you call Nickserv to help you. As can be seen it one of the half a dozen bots that helps IRC. So the first thing you need to do is
/msg nickserv help
what you are doing is asking nickserv what services they have and Nickserv shares the numbers of services it offers. After looking into, you are looking for register
/msg nickerv register
Both the commands tell you what you need to do as can be seen by this
Let s say you are XYZ and your e-mail address is xyz@xyz.com This is just a throwaway id I am taking for the purpose of showing how the process is done. For this, also assume your passowrd is 1234xyz;0x something like this. I have shared about APG (Advanced Password Generator) before so you could use that to generate all sorts of passwords for yourself.
So next would be
/msg nickserv register 1234xyz;0x xyz@xyz.com
Now the thing to remember is you need to be sure that the email is valid and in your control as it would generate a link with hcaptcha. Interestingly, their accessibility signup fails or errors out. I just entered my email and it errors out. Anyway back to it. Even after completing the puzzle, even with the valid username and password neither pidgin or hexchat would let me in. Neither of the clients were helpful in figuring out what was going wrong.
At this stage, I decided to see the specs of ircv3 if they would help out in anyway and came across this. One would have thought that this is one of the more urgent things that need to be fixed, but for reasons unknown it s still in draft mode. Maybe they (the participants) are not in consensus, no idea. Unfortunately, it seems that the participants of IRCv3 have chosen a sort of closed working model as the channel is restricted. The only notes of any consequence are being shared by Ilmari Lauhakangas from Finland. Apparently, Mr/Ms/they Ilmari is also a libreoffice hacker. It is possible that their is or has been lot of drama before or something and that s why things are the way they are. In either way, doesn t tell me when this will be fixed, if ever. For people who are on mobiles and whatnot, without element, it would be 10x times harder.
Update :- Saw this discussion on github. Don t see a way out
It seems I would be unable to unable to be part of Debconf Kochi 2023. Best of luck to all the participants and please share as much as possible of what happens during the event.
About 6 months ago, I decided to purchase a bike trailer. I don't drive and
although I also have a shopping caddy, it often can't handle a week's
groceries.
Since the goal for the trailer was to haul encumbering and heavy loads, I
decided to splurge and got a Surly Ted. The 32" x 24" flat bed is very
versatile and the trailer is rated for up to 300 lbs (~135 kg).
At around 30 lbs (~13.5 kg), the trailer itself is light enough for me to climb
up the stairs to my apartment with it.
Having seldom driven a bike trailer before, I was at first worried about its
handling and if it would jerk me around (as some children's chariots tend to).
I'm happy to report the two pronged hitch Surly designed works very
well and lets you do 180 turns effortlessly.
So far, I've used the trailer to go grocery shopping, buy bulk food and haul
dirt and mulch. To make things easier, I've purchased two 45L storing
crates from Home Depot and added two planks of wood on each side of
the trailer to stabilise things when I strap the crates down to the bed.
Since my partner and I are subscribed to an organic farmer's box during the
summer and get baskets from Lufa during the winter, picking up our
groceries at the pick-up point is as easy as dumping our order in the storing
crates and strapping them back to the trailer.
Although my housing cooperative has a (small) indoor bicycle parking space, my
partner uses our spot during the summer, which means I have to store the
trailer on my balcony. To make things more manageable and free up some space, I
set up a system of pulleys to hoist the trailer up the air when it's not in
use.
I did go through a few iterations, but I'm pretty happy with the current 8
pulleys block and tackle mechanism I rigged.
All and all, this trailer wasn't cheap, but I regret nothing. Knowing Surley's
reputation, it will last me many years and not having to drive a car to get
around always ends up being the cheaper solution.
This post describes how to deploy cilium (and
hubble) using docker on a Linux system with
k3d or kind to test it as
CNI and
Service Mesh.
I wrote some scripts to do a local installation and evaluate cilium to use it
at work (in fact we are using cilium on an EKS
cluster now), but I thought it would be a good idea to share my original
scripts in this blog just in case they are useful to somebody, at least for
playing a little with the technology.
LinksAs there is no point on explaining here all the concepts related to cilium
I m providing some links for the reader interested on reading about it:
All the scripts and configuration files discussed in this post are available on
my cilium-docker git repository.
InstallationFor each platform we are going to deploy two clusters on the same docker
network; I ve chosen this model because it allows the containers to see the
addresses managed by metallb from both clusters (the idea
is to use those addresses for load balancers and treat them as if they were
public).
The installation(s) use cilium as CNI, metallb for BGP (I tested the
cilium options, but I wasn t able to configure them right) and nginx as the
ingress controller (again, I tried to use cilium but something didn t work
either).
To be able to use the previous components some default options have been
disabled on k3d and kind and, in the case of k3d, a lot of k3s options
(traefik, servicelb, kubeproxy, network-policy, ) have also been
disabled to avoid conflicts.
To use the scripts we need to install cilium, docker, helm, hubble,
k3d, kind, kubectl and tmpl in our system.
After cloning the repository, the sbin/tools.sh
script can be used to do that on a linux-amd64 system:
Once we have the tools, to install everything on k3d (for kind replace
k3d by kind) we can use the
sbin/cilium-install.sh script as
follows:
$# Deploy first k3d cluster with cilium & cluster-mesh$./sbin/cilium-install.sh k3d 1 full
[...]
$# Deploy second k3d cluster with cilium & cluster-mesh$./sbin/cilium-install.sh k3d 2 full
[...]
$# The 2nd cluster-mesh installation connects the clusters
If we run the command cilium status after the installation we should get an
output similar to the one seen on the following screenshot:
The installation script uses the following templates:
tmpl/cilium.yaml: values to deploy the
cilium using the helm chart.
Once we have finished our tests we can remove the installation using the
sbin/cilium-remove.sh script.
Some notes about the configuration
As noted on the documentation, the cilium deployment needs to mount the
bpffs on /sys/fs/bpf and cgroupv2 on /run/cilium/cgroupv2; that is
done automatically on kind, but fails on k3d because the image does not
include bash (see this issue).To fix it we mount a script on all the k3d containers that is executed each
time they are started (the script is mounted as /bin/k3d-entrypoint-cilium.sh
because the /bin/k3d-entrypoint.sh script executes the scripts that follow
the pattern /bin/k3d-entrypoint-*.sh before launching the k3s daemon).
The source code of the script is available
here.
When testing the multi-cluster deployment with k3d we have found issues
with open files, looks like they are related to inotify (see
this
page on the kind documentation); adding the following to the
/etc/sysctl.conf file fixed the issue:
# fix inotify issues with docker & k3d
fs.inotify.max_user_watches=524288fs.inotify.max_user_instances=512
Although the deployment theoretically supports it, we are not using cilium
as the cluster ingress yet (it did not work, so it is no longer enabled)
and we are also ignoring the gateway-api for now.
The documentation uses the cilium cli to do all the installations, but I
noticed that following that route the current version does not work right with
hubble (it messes up the TLS support, there are some notes about the
problems on this cilium
issue), so we are deploying with helm right now.The problem with the helm approach is that there is no official documentation
on how to install the cluster mesh with it (there is a request for
documentation here), so we are
using the cilium cli for now and it looks that it does not break the hubble
configuration.
TestsTo test cilium we have used some scripts & additional config files that are
available on the test sub directory of the repository:
cilium-connectivity.sh: a script
that runs the cilium connectivity test for one cluster or in multi cluster
mode (for mesh testing).If we export the variable HUBBLE_PF=true the script executes the command
cilium hubble port-forward before launching the tests.
http-sw.sh: Simple tests for cilium policies
from the cilium demo;
the script deploys the Star Wars demo application and allows us to add the
L3/L4 policy or the L3/L4/L7 policy, test the connectivity and view the
policies.
ingress-basic.sh: This test is for
checking the ingress controller, it is prepared to work against cilium and
nginx, but as explained before the use of cilium as an ingress controller
is not working as expected, so the idea is to call it with nginx always as
the first argument for now.
mesh-test.sh: Tool to deploy a global
service on two clusters, change the service affinity to local or remote,
enable or disable if the service is shared and test how the tools respond.
Running the testsThe cilium-connectivity.sh executes the standard cilium tests:
$./test/cilium-connectivity.sh k3d 12
Monitor aggregation detected, will skip some flow validation
steps
[k3d-cilium1] Creating namespace cilium-test for connectivity
check...
[k3d-cilium2] Creating namespace cilium-test for connectivity
check...
[...]
All 33 tests (248 actions) successful, 2 tests skipped,
0 scenarios skipped.
To test how the cilium policies work use the http-sw.sh script:
kubectx k3d-cilium2 #(just in case)#Create test namespace and services
./test/http-sw.sh create
#Test without policies (exaust-port fails by design)./test/http-sw.sh test
#Create and view L3/L4 CiliumNetworkPolicy
./test/http-sw.sh policy-l34
#Test policy (no access from xwing, exaust-port fails)./test/http-sw.sh test
#Create and view L7 CiliumNetworkPolicy
./test/http-sw.sh policy-l7
#Test policy (no access from xwing, exaust-port returns 403)./test/http-sw.sh test
#Delete http-sw test./test/http-sw.sh delete
And to see how the service mesh works use the mesh-test.sh script:
#Create services on both clusters and test./test/mesh-test.sh k3d create
./test/mesh-test.sh k3d test
#Disable service sharing from cluster 1 and test./test/mesh-test.sh k3d svc-shared-false
./test/mesh-test.sh k3d test
#Restore sharing, set local affinity and test./test/mesh-test.sh k3d svc-shared-default
./test/mesh-test.sh k3d svc-affinity-local
./test/mesh-test.sh k3d test
#Delete deployment from cluster 1 and test./test/mesh-test.sh k3d delete-deployment
./test/mesh-test.sh k3d test
#Delete test./test/mesh-test.sh k3d delete
WordPress Cookies, Debdelta
One of the most irritating things about WordPress is whenever I start a firefox session, WordPress aks for cookie selection. I make my choices but it s not persistent. The next session the same thing happens again. It does keep my identity but for some unknown reason doesn t respect the Cookie selection. I usually use Firefox ESR (102.13.0esr-1) on Testing.
Also, for more than a week I have found debdelta not working as it should. To give a brief history, the idea of debdelta is to save bandwidth, whether it 100 kbps or 1 mbit or whatever, the moment you give debdelta-upgrade it will try to see if there is a delta of the debs that you want to upgrade. The sequence is as follows or at least that is what I do
$sudo apt update (updates the index files of apt and tells you how many packages are upgradable). IIRC, every 4-5 hours there is an index runs that basically catches any new debian packages. You can see the index generated dynamically each time you run the above command in /var/lib/apt/lists
2. $ sudo debdelta-upgrade Now the debdelta algorithim goes to work. Debdelta has its own mirror. I think sometime after the indexes are updated, debdelta does it own run, probably an hour or two later. The algorithim sees how big the diff between the two packages and generates a delta. If the generated delta (diff.) between the old and the new is less than 70% then the generated delta is kept or otherwise thrown. The delta is kept in debdelta mirror. You can from 1 day history how big it is. And AFAIK, it is across all the hardware and platforms that Debian supports. My issue has been simply that debdelta just doesn t work and even after debdelta-upgrade I am forced to get all the files from the server. Have shared more details here.
3. The last step is $ sudo aptitude upgrade or $ sudo aptitude install and give package names if you know some packages are broken or non-resolvable or have some bugs.
RISC
I had shared about RISC chips couple of weeks back. One of the things that I had forgotten to share that Android is also supporting RISC-V few months back. How I forgot that crucial bit of info. is beyond me. There are number of RISC-V coming out in the next few months to early 2024. One of the more interesting boards that came up in 2021/2022 was HiFive Unmatched. The problem is that the board although interesting on specs is out of reach of most Indians. I am sure most people would be aware of the chicken and egg problem and that is where it is. Pricing will be key component. If they get the pricing right and are able to produce in good numbers, we might see more of these boards soon. At least with Android that issue gets somewhat resolved. There is possibility that we may see more Android set-top boxes and whatnot paired with RISC paving more money for RISC development and a sort of virtuous cycle. While I m in two minds, I decide not to share what chips are coming unless and until we know what the pricing is, otherwise they just become part of a hype cycle. But it s definitely something to watch out for. One of the more interesting articles that I read last week also tells how Linux has crossed 3% desktop space and his views on the same. I do very much agree with his last paragraph but at the same time biased as am an old time desktop user. I just don t find myself happy on small factor keyboards. I will leave the rest for some other time depending how things happen.
Manipur
Before I start sharing about Manipur, I should thank Praveen A. few years back, Praveen wanted to see the 7 sisters and in fact had even proposed to partially sponsor me so that we could together visit the 7 states of North-East. For reasons I don t remember, I just wasn t able to go. Probably some work and responsibilities at home. For almost 2.5 months now, Manipur, one of the States in the 7 states has been burning. There have been talks and sharing of genocidial murder of Christians in Manipur. This is not just me or some random person talking about, even BJP (the ruling party in the Center), their functionaries both in Manipur and its neighboring state Mizoram have been sharing. Mizoram s State BJP President in fact resigned just few days back saying it s state sponsored activity. Couple of days back, European Parliament held a session about Manipur and even passed a resolution. The BJP tried to hit back saying Colonial Mindset but when asked if it s the same when India invited European Parliamentarians to visit Kashmir in 2019, the silence is deafening. The Wire has interviewed all the prominent leaders and sort of players in Manipur politics but apart from calling Kukis foreigners they have no proof. In one of the interviews one of the Meitei leaders calls Kuki s foreigners but doesn t have any Government data to support his belief. The census of India was last held in 2011. People from the civil society have time and again asked the Government to do the census but GOI has been giving one excuse after another. They in fact, wanted to do a caste census but that too they themselves took on back foot probably as they believe that both census may give results not to their liking. In fact, this Government is also known as No Data Government as almost in everything, it denies data. I am not going to go to that otherwise would not be able to complete blog post till couple of days. I will just share this bit of info. that this Govt. hasn t given Household Consumption Survey data for last four years. Going back to the topic though, neither the Prime Minister, the Home Minister, the Defence Minister nobody has been able to utter the word Manipur till date. I have no idea when they will wake up. People from all ethnicities have tried to make representations to GOI but no one has been able to meet them, neither the Kukis, nor the Nagas, nor the Meiteis even though it is a sensitive border area.
Libraries in Kerala
I wanted to end on a somewhat positive note. So just a few days back, the Miinistry of Culture shared the number of Libraries per state. As can be seen from the infographic, Kerala is a giant in that. If I do find a table, would share that as well, so those who can t see can hear the data. Till later.
Utkarsh Gupta
did 0.0h (out of 0h assigned and 25.5h from previous period), thus carrying over 25.5h to the next month.
Evolution of the situation
In June, we have released 40 DLAs.
Notable security updates in June included mariadb-10.3, openssl, and golang-go.crypto. The mariadb-10.3 package was synchronized with the latest upstream maintenance release, version 10.3.39. The openssl package was patched to correct several flaws with certificate validation and with object identifier parsing. Finally, the golang-go.crypto package was updated to address several vulnerabilities, and several associated Go packages were rebuilt in order to properly incorporate the update.
LTS contributor Sylvain has been hard at work with some behind-the-scenes improvements to internal tooling and documentation. His efforts are helping to improve the efficiency of all LTS contributors and also helping to improve the quality of their work, making our LTS updates more timely and of higher quality.
LTS contributor Lee Garrett began working on a testing framework specifically for Samba. Given the critical role which Samba plays in many deployments, the tremendous impact which regressions can have in those cases, and the unique testing requirements of Samba, this work will certainly result in increased confidence around our Samba updates for LTS.
LTS contributor Emilio Pozuelo Monfort has begun preparatory work for the upcoming Firefox ESR version 115 release. Firefox ESR (and the related Thunderbird ESR) requires special work to maintain up to date in LTS. Mozilla do not release individual patches for CVEs, and our policy is to incorporate new ESR releases from Mozilla into LTS. Most updates are minor updates, but once a year Mozilla will release a major update as they move to a new major version for ESR. The update to a new major ESR version entails many related updates to toolchain and other packages. The preparations that Emilio has begun will ensure that once the 115 ESR release is made, updated packages will be available in LTS with minimal delay.
Another highlight of behind-the-scenes work is our Front Desk personnel. While we often focus on the work which results in published package updates, much work is also involved in reviewing new vulnerabilities and triaging them (i.e., determining if they affect one or more packages in LTS and then determining the severity of those which are applicable). These intrepid contributors (Emilio Pozuelo Monfort, Markus Koschany, Ola Lundqvist, Sylvain Beucler, and Thorsten Alteholz for the month of June) reviewed dozens of vulnerabilities and made decisions about how those vulnerabilities should be dealt with.
PLIO
I have been looking for an image viewer that can view images via modification date by default. The newer, the better. Alas, most of the image viewers do not do that. Even feh somehow fails. What I need is default listing of images as thumbnails by modification date. I put it up on Unix Stackexchange couple of years ago. Somebody shared ristretto but that just gives listing and doesn t give the way I want it. To be more illustrative, maybe this may serve as a guide to what I mean.
There is an RFP for it. While playing with it, I also discovered another benefit of the viewer, a sort of side-benefit, it tells you if any images have gone corrupt or whatever and you get that info. on the CLI so you can try viewing that image with the path using another viewer or viewers before deleting them. One of the issues is there doesn t seem to be a magnify option by default. While the documentation says use the ^ key to maximize it, it doesn t maximize. Took me a while to find it as that isn t a key that I use most of the time. Ironically, that is the key used on the mobile quite a bit. Anyways, so that needs to be fixed. Sadly, it doesn t have creation date or modification date sort, although the documentation does say it does (at least the modification date) but it doesn t show at my end. I also got Warning: UNKNOWN command detected! but that doesn t tell me enough as to what the issue is. Hopefully the developer will fix the issues and it will become part of Debian as many such projects are. Compiling was dead easy even with gcc-12 once I got freeimage-dev.
Mum s first death anniversary
I do not know where the year went by or how. The day went in a sort of suspended animation. The only thing I did was eat and sleep that day, didn t feel like doing anything. Old memories, even dreams of fighting with her only to realize in the dream itself it s fake, she isn t there anymore Something that can never be fixed
Debconf Kochi
I should have shared it few days ago but somehow slipped my mind. While it s too late for most people to ask for bursary for Debconf Kochi, if you are anywhere near Kochi in the month of September between the dates. September 3 to September 17 nearby Infopark, Kochi you could walk in and talk to people. This would be for people who either have an interest in free software, FOSS or Debian specific. For those who may not know, while Debian is a Linux Distribution having ports to other kernels as well as well as hardware. While I may not be able to provide the list of all the various flavors as well as hardware, can say it is quite a bit. For e.g. there is a port to RISC-V that was done few years back (2018). Why that is needed will be shared below. There is always something new to look forward in a Debconf.
Pressure Cooker and Potatoes
This was asked to me in the last Debconf (2016) by few people. So as people are coming to India, it probably is a good time to sort of reignite the topic :). So a Pressure Cooker boils your veggies and whatnot while still preserving the nutrients. While there are quite a number of brands I would suggest either Prestige or Hawkins, I have had good experience with both. There are also some new pressure cookers that have come that are somewhat in the design of the Thai Wok. So if that is something that you are either comfortable with or looking for, you could look at that. One of the things that you have to be sort of aware of and be most particular is the pressure safety valve. Just putting up pressure cooker safety valve in your favorite search-engine should show you different makes and whatnot. While they are relatively cheap, you need to see it is not cracked, used or whatever. The other thing is the Pressure Cooker whistle as well. The easiest thing to cook are mashed potatoes in a pressure cooker. A pressure Cooker comes in Litres, from 1 Ltr. to 20 Ltr. The larger ones are obviously for hotels or whatnot. General rule of using Pressure cooker is have water 1/4th, whatever vegetable or non-veg you want to boil 1/2 and let the remaining part for the steam. Now the easiest thing to do is have wash the potatoes and put 1/4th water of the pressure cooker. Then put 1/2 or less or little bit more of the veggies, in this instance just Potatoes. You can put salt to or that can be done later. The taste will be different. Also, there are various salts so won t really go into it as spices is a rabbit hole. Anyways, after making sure that there is enough space for the steam to be built, Put the handle on the cooker and basically wait for 5-10 minutes for the pressure to be built. You will hear a whistling sound, wait for around 5 minutes or a bit more (depends on many factors, kind of potatoes, weather etc.) and then just let it cool off naturally. After 5-10 minutes or a bit more, the pressure will be off. Your mashed potatoes are ready for either consumption or for further processing. I am assuming gas, induction cooking will have its own temperature, have no idea about it, hence not sharing that. Pressure Cooker, first put on the heaviest settings, once it starts to whistle, put it on medium for 5-10 minutes and then let it cool off. The first time I had tried that, I burned the cooker. You understand things via trial and error.
Poha recipe
This is a nice low-cost healthy and fulfilling breakfast called Poha that can be made anytime and requires at the most 10-15 minutes to prepare with minimal fuss. The main ingredient is Poha or flattened rice. So how is it prepared. I won t go into the details of quantity as that is upto how hungry people are. There are various kinds of flattened rice available in the market, what you are looking for is called thick Poha or zhad Poha (in Marathi). The first step is the trickiest. What do you want to do is put water on Poha but not to let it be soggy. There is an accessory similar to tea filter but forgot the name, it basically drains all the extra moisture and you want Poha to be a bit fluffy and not soggy. The Poha should breathe for about 5 minutes before being cooked. To cook, use a heavy bottomed skillet, put some oil in it, depends on what oil you like, again lot of variations, you can use ground nut or whatever oil you prefer. Then use single mustard seeds to check temperature of the oil. Once the mustard seeds starts to pop, it means it s ready for things. So put mustard seeds in, finely chopped onion, finely chopped coriander leaves, a little bit of lemon juice, if you want potatoes, then potatoes too. Be aware that Potatoes will soak oil like anything, so if you are going to have potatoes than the oil should be a bit more. Some people love curry leaves, others don t. I like them quite a bit, it gives a slightly different taste. So the order is
Oil
Mustard seeds (1-2 teaspoon)
Curry leaves 5-10
Onion (2-3 medium onions finely chopped, onion can also be used as garnish.)
Potatoes (2-3 medium ones, mashed)
Small green chillies or 1-2 Red chillies (if you want)
Coriander Leaves (one bunch finely chopped)
Peanuts (half a glass)
Make sure that you are stirring them quite a bit. On a good warm skillet, this should hardly take 5 minutes. Once the onions are slighly brown, you are ready to put Poha in. So put the poha, add turmeric, salt, and sugar. Again depends on number of people. If I made for myself and mum, usually did 1 teaspoon of salt, not even one fourth of turmeric, just a hint, it is for the color, 1 to 2 teapoons of sugar and mix them all well at medium flame. Poha used to be two or three glasses.
If you don t want potato, you can fry them a bit separately and garnish with it, along with coriander, coconut and whatnot. In Kerala, there is possibility that people might have it one day or all days. It serves as a snack at anytime, breakfast, lunch, tea time or even dinner if people don t want to be heavy. The first few times I did, I did manage to do everything wrong. So, if things go wrong, let it be. After a while, you will find your own place. And again, this is just one way, I m sure this can be made as elaborate a meal as you want. This is just something you can do if you don t want noodles or are bored with it. The timing is similar.
While I don t claim to be an expert in cooking in anyway or form, if people have questions feel free to ask. If you are single or two people, 2 Ltr. Pressure cooker is enough for most Indians, Westerners may take a slightly bit larger Pressure Cooker, maybe a 3 Ltr. one may be good for you. Happy Cooking and Experimenting
I have had the pleasure to have Poha in many ways. One of my favorite ones is when people have actually put tadka on top of Poha. You do everything else but in a slight reverse order. The tadka has all the spices mixed and is concentrated and is put on top of Poha and then mixed. Done right, it tastes out of this world. For those who might not have had the Indian culinary experience, most of which is actually borrowed from the Mughals, you are in for a treat.
One of the other things I would suggest to people is to ask people where there can get five types of rice. This is a specialty of South India and a sort of street food. I know where you can get it Hyderabad, Bangalore, Chennai but not in Kerala, although am dead sure there is, just somehow have missed it. If asked, am sure the Kerala team should be able to guide.
That s all for now, feeling hungry, having dinner as have been sharing about cooking.
RISC-V
There has been lot of conversations about how India could be in the microprocesor spacee. The x86 and x86-64 is all tied up in Intel and AMD so that s a no go area. Let me elaborate a bit why I say that. While most of the people know that IBM was the first producers of transistors as well as microprocessors. Coincidentally, AMD and Intel story are similar in some aspects but not in others. For a long time Intel was a market leader and by hook or crook it remained a market leader. One of the more interesting companies in the 1980s was Cyrix which sold lot of low-end microprocessors. A lot of that technology also went into Via which became a sort of spiritual successor of Cyrix. It is because of Cyrix and Via that Intel was forced to launch the Celeron model of microprocessors.
Lawsuits, European Regulation
For those who have been there in the 1990s may have heard the term Wintel that basically meant Microsoft Windows and Intel and they had a sort of monopoly power. While the Americans were sorta ok with it, the Europeans were not and time and time again they forced both Microsoft as well as Intel to provide alternatives. The pushback from the regulators was so great that Intel funded AMD to remain solvent for few years. The successes that we see today from AMD is Lisa Su s but there is a whole lot of history as well as bad blood between the two companies. Lot of lawsuits and whatnot. Lot of cross-licensing agreements between them as well. So for any new country it would need lot of cash just for licensing all the patents there are and it s just not feasible for any newcomer to come in this market as they would have to fork the cash for the design apart from manufacturing fab.
ARM
Most of the mobiles today sport an ARM processor. At one time it meant Advanced RISC Machines but now goes by Arm Ltd. Arm itself licenses its designs and while there are lot of customers, you are depending on ARM and they can change any of the conditions anytime they want. You are also hoping that ARM does not steal your design or do anything else with it. And while people trust ARM, it is still a risk if you are a company.
RISC and Shakti
There is not much to say about RISC other than this article at Register. While India does have large ambitions, executing it is far trickier than most people believe as well as complex and highly capital intensive. The RISC way could be a game-changer provided India moves deftly ahead. FWIW, Debian did a RISC port in 2018. From what I can tell, you can install it on a VM/QEMU and do stuff. And while RISC has its own niches, you never know what happens next.One can speculate a lot and there is certainly a lot of momentum behind RISC. From what little experience I have had, where India has failed time and time again, whether in software or hardware is support. Support is the key, unless that is not fixed, it will remain a dream
On a slightly sad note, Foxconn is withdrawing from the joint venture it had with Vedanta.
Tobias Frost
did 16.0h (out of 15.0h assigned and 1.0h from previous period).
Utkarsh Gupta
did 5.5h (out of 5.0h assigned and 26.0h from previous period), thus carrying over 25.5h to the next month.
Evolution of the situation
In May, we have released 34 DLAs.
Several of the DLAs constituted notable security updates to LTS during the month of May. Of particular note were the linux (4.19) and linux-5.10 packages, both of which addressed a considerable number of CVEs. Additionally, the postgresql-11 package was updated by synchronizing it with the 11.20 release from upstream.
Notable non-security updates were made to the distro-info-data database and the timezone database. The distro-info-data package was updated with the final expected release date of Debian 12, made aware of Debian 14 and Ubuntu 23.10, and was updated with the latest EOL dates for Ubuntu releases. The tzdata and libdatetime-timezone-perl packages were updated with the 2023c timezone database. The changes in these packages ensure that in addition to the latest security updates LTS users also have the latest information concerning Debian and Ubuntu support windows, as well as the latest timezone data for accurate worldwide timekeeping.
LTS contributor Anton implemented an improvement to the Debian Security Tracker Unfixed vulnerabilities in unstable without a filed bug view, allowing for more effective management of CVEs which do not yet have a corresponding bug entry in the Debian BTS.
LTS contributor Sylvain concluded an audit of obsolete packages still supported in LTS to ensure that new CVEs are properly associated. In this case, a package being obsolete means that it is no longer associated with a Debian release for which the Debian Security Team has direct responsibility. When this occurs, it is the responsibility of the LTS team to ensure that incoming CVEs are properly associated to packages which exist only in LTS.
Finally, LTS contributors also contributed several updates to packages in unstable/testing/stable to fix CVEs. This helps package maintainers, addresses CVEs in current and future Debian releases, and ensures that the CVEs do not remain open for an extended period of time only for the LTS team to be required to deal with them much later in the future.
Thanks to our sponsors
Sponsors that joined recently are in bold.
Debian v12 with codename bookworm was released as new stable release on 10th of June 2023. Similar to what we had with #newinbullseye and previous releases, now it s time for #newinbookworm!
I was the driving force at several of my customers to be well prepared for bookworm. As usual with major upgrades, there are some things to be aware of, and hereby I m starting my public notes on bookworm that might be worth also for other folks. My focus is primarily on server systems and looking at things from a sysadmin perspective.
Further readings
As usual start at the official Debian release notes, make sure to especially go through What s new in Debian 12 + Issues to be aware of for bookworm.
Package versions
As a starting point, let s look at some selected packages and their versions in bullseye vs. bookworm as of 2023-02-10 (mainly having amd64 in mind):
Package
bullseye/v11
bookworm/v12
ansible
2.10.7
2.14.3
apache
2.4.56
2.4.57
apt
2.2.4
2.6.1
bash
5.1
5.2.15
ceph
14.2.21
16.2.11
docker
20.10.5
20.10.24
dovecot
2.3.13
2.3.19
dpkg
1.20.12
1.21.22
emacs
27.1
28.2
gcc
10.2.1
12.2.0
git
2.30.2
2.39.2
golang
1.15
1.19
libc
2.31
2.36
linux kernel
5.10
6.1
llvm
11.0
14.0
lxc
4.0.6
5.0.2
mariadb
10.5
10.11
nginx
1.18.0
1.22.1
nodejs
12.22
18.13
openjdk
11.0.18 + 17.0.6
17.0.6
openssh
8.4p1
9.2p1
openssl
1.1.1n
3.0.8-1
perl
5.32.1
5.36.0
php
7.4+76
8.2+93
podman
3.0.1
4.3.1
postfix
3.5.18
3.7.5
postgres
13
15
puppet
5.5.22
7.23.0
python2
2.7.18
(gone!)
python3
3.9.2
3.11.2
qemu/kvm
5.2
7.2
ruby
2.7+2
3.1
rust
1.48.0
1.63.0
samba
4.13.13
4.17.8
systemd
247.3
252.6
unattended-upgrades
2.8
2.9.1
util-linux
2.36.1
2.38.1
vagrant
2.2.14
2.3.4
vim
8.2.2434
9.0.1378
zsh
5.8
5.9
Linux Kernel
The bookworm release ships a Linux kernel based on version 6.1, whereas bullseye shipped kernel 5.10. As usual there are plenty of changes in the kernel area, including better hardware support, and this might warrant a separate blog entry, but to highlight some changes:
See Kernelnewbies.org for further changes between kernel versions.
Configuration management
puppet s upstream sadly still doesn t provide packages for bookworm (see PA-4995), though Debian provides puppet-agent and puppetserver packages, and even puppetdb is back again, see release notes for further information.
ansible is also available and made it with version 2.14 into bookworm.
Prometheus stack
Prometheus server was updated from v2.24.1 to v2.42.0 and all the exporters that got shipped with bullseye are still around (in more recent versions of course).
Virtualization
docker (v20.10.24), ganeti (v3.0.2-3), libvirt (v9.0.0-4), lxc (v5.0.2-1), podman (v4.3.1), openstack (Zed), qemu/kvm (v7.2), xen (v4.17.1) are all still around.
Vagrant is available in version 2.3.4, also Vagrant upstream provides their packages for bookworm already.
If you re relying on VirtualBox, be aware that upstream doesn t provide packages for bookworm yet (see ticket 21524), but thankfully version 7.0.8-dfsg-2 is available from Debian/unstable (as of 2023-06-10) (VirtualBox isn t shipped with stable releases since quite some time due to lack of cooperation from upstream on security support for older releases, see #794466).
rsync
rsync was updated from v3.2.3 to v3.2.7, and we got a few new options:
--fsync: fsync every written file
--old-dirs: works like dirs when talking to old rsync
--old-args: disable the modern arg-protection idiom
--secluded-args, -s: use the protocol to safely send the args (replaces protect-args option)
--trust-sender: trust the remote sender s file list
OpenSSH
OpenSSH was updated from v8.4p1 to v9.2p1, so if you re interested in all the changes, check out the release notes between those version (8.5, 8.6, 8.7, 8.8, 8.9, 9.0, 9.1 + 9.2). Let s highlight some notable new features:
ssh(1): when prompting the user to accept a new hostkey, display any other host names/addresses already associated with the key
ssh(1): allow UserKnownHostsFile=none to indicate that no known_hosts file should be used to identify host keys
ssh(1): add a ssh_config KnownHostsCommand option that allows the client to obtain known_hosts data from a command in addition to the usual files
ssh(1), sshd(8): add a RequiredRSASize directive to set a minimum RSA key length
ssh(1): add a host line to the output of ssh -G showing the original hostname argument
ssh-keygen -A (generate all default host key types) will no longer generate DSA keys
ssh-keyscan(1): allow scanning of complete CIDR address ranges, e.g. ssh-keyscan 192.168.0.0/24
One important change you might wanna be aware of is that as of OpenSSH v8.8, RSA signatures using the SHA-1 hash algorithm got disabled by default, but RSA/SHA-256/512 AKA RSA-SHA2 gets used instead. OpenSSH has supported RFC8332 RSA/SHA-256/512 signatures since release 7.2 and existing ssh-rsa keys will automatically use the stronger algorithm where possible. A good overview is also available at SSH: Signature Algorithm ssh-rsa Error.
Now tools/libraries not supporting RSA-SHA2 fail to connect to OpenSSH as present in bookworm. For example python3-paramiko v2.7.2-1 as present in bullseye doesn t support RSA-SHA2. It tries to connect using the deprecated RSA-SHA-1, which is no longer offered by default with OpenSSH as present in bookworm, and then fails. Support for RSA/SHA-256/512 signatures in Paramiko was requested e.g. at #1734, and eventually got added to Paramiko and in the end the change made it into Paramiko versions >=2.9.0. Paramiko in bookworm works fine, and a backport by rebuilding the python3-paramiko package from bookworm for bullseye solves the problem (BTDT).
Misc unsorted
new non-free-firmware component/repository (see Debian Wiki for details)
support only the merged-usr root filesystem layout (see Debian Wiki for details)
the asterisk package didn t make it into bookworm (see #1031046)
e2fsprogs: the breaking change related to metadata_csum_seed and orphan_file (see #1031325) was reverted with v1.47.0-2 for bookworm (also see #1031622 + #1030939)
crmadmin of pacemaker no longer interprets the timeout option (-t/ timeout) in milliseconds (as it used to be until v2.0.5), but as of v2.1.0 (and v2.1.5 is present in bookworm) it now interprets the argument as second by default
Thanks to everyone involved in the release, happy upgrading to bookworm, and let s continue with working towards Debian/trixie. :)
I have several TB worth of family photos, videos, and other data. This needs to be backed up and archived.
Backups and archives are often thought of as similar. And indeed, they may be done with the same tools at the same time. But the goals differ somewhat:
Backups are designed to recover from a disaster that you can fairly rapidly detect.
Archives are designed to survive for many years, protecting against disaster not only impacting the original equipment but also the original person that created them.
Reflecting on this, it implies that while a nice ZFS snapshot-based scheme that supports twice-hourly backups may be fantastic for that purpose, if you think about things like family members being able to access it if you are incapacitated, or accessibility in a few decades time, it becomes much less appealing for archives. ZFS doesn t have the wide software support that NTFS, FAT, UDF, ISO-9660, etc. do.
This post isn t about the pros and cons of the different storage media, nor is it about the pros and cons of cloud storage for archiving; these conversations can readily be found elsewhere. Let s assume, for the point of conversation, that we are considering BD-R optical discs as well as external HDDs, both of which are too small to hold the entire backup set.
What would you use for archiving in these circumstances?
Establishing goals
The goals I have are:
Archives can be restored using Linux or Windows (even though I don t use Windows, this requirement will ensure the broadest compatibility in the future)
The archival system must be able to accommodate periodic updates consisting of new files, deleted files, moved files, and modified files, without requiring a rewrite of the entire archive dataset
Archives can ideally be mounted on any common OS and the component files directly copied off
Redundancy must be possible. In the worst case, one could manually copy one drive/disc to another. Ideally, the archiving system would automatically track making n copies of data.
While a full restore may be a goal, simply finding one file or one directory may also be a goal. Ideally, an archiving system would be able to quickly tell me which discs/drives contain a given file.
Ideally, preserves as much POSIX metadata as possible (hard links, symlinks, modification date, permissions, etc). However, for the archiving case, this is less important than for the backup case, with the possible exception of modification date.
Must be easy enough to do, and sufficiently automatable, to allow frequent updates without error-prone or time-consuming manual hassle
I would welcome your ideas for what to use. Below, I ll highlight different approaches I ve looked into and how they stack up.
Basic copies of directories
The initial approach might be one of simply copying directories across. This would work well if the data set to be archived is smaller than the archival media. In that case, you could just burn or rsync a new copy with every update and be done. Unfortunately, this is much less convenient with data of the size I m dealing with. rsync is unavailable in that case. With some datasets, you could manually design some rsyncs to store individual directories on individual devices, but that gets unwieldy fast and isn t scalable.
You could use something like my datapacker program to split the data across multiple discs/drives efficiently. However, updates will be a problem; you d have to re-burn the entire set to get a consistent copy, or rely on external tools like mtree to reflect deletions. Not very convenient in any case.
So I won t be using this.
tar or zip
While you can split tar and zip files across multiple media, they have a lot of issues. GNU tar s incremental mode is clunky and buggy; zip is even worse. tar files can t be read randomly, making it extremely time-consuming to extract just certain files out of a tar file.
The only thing going for these formats (and especially zip) is the wide compatibility for restoration.
dar
Here we start to get into the more interesting tools. Dar is, in my opinion, one of the best Linux tools that few people know about. Since I first wrote about dar in 2008, it s added some interesting new features; among them, binary deltas and cloud storage support. So, dar has quite a few interesting features that I make use of in other ways, and could also be quite helpful here:
Dar can both read and write files sequentially (streaming, like tar), or with random-access (quick seek to extract a subset without having to read the entire archive)
Dar can apply compression to individual files, rather than to the archive as a whole, faciliting both random access and resilience (corruption in one file doesn t invalidate all subsequent files). Dar also supports numerous compression algorithms including gzip, bzip2, xz, lzo, etc., and can omit compressing already-compressed files.
The end of each dar file contains a central directory (dar calls this a catalog). The catalog contains everything necessary to extract individual files from the archive quickly, as well as everything necessary to make a future incremental archive based on this one. Additionally, dar can make and work with isolated catalogs a file containing the catalog only, without data.
Dar can split the archive into multiple pieces called slices. This can best be done with fixed-size slices ( slice and first-slice options), which let the catalog regord the slice number and preserves random access capabilities. With the execute option, dar can easily wait for a given slice to be burned, etc.
Dar normally stores an entire new copy of a modified file, but can optionally store an rdiff binary delta instead. This has the potential to be far smaller (think of a case of modifying metadata for a photo, for instance).
Additionally, dar comes with a dar_manager program. dar_manager makes a database out of dar catalogs (or archives). This can then be used to identify the precise archive containing a particular version of a particular file.
All this combines to make a useful system for archiving. Isolated catalogs are tiny, and it would be easy enough to include the isolated catalogs for the entire set of archives that came before (or even the dar_manager database file) with each new incremental archive. This would make restoration of a particular subset easy.
The main thing to address with dar is that you do need dar to extract the archive. Every dar release comes with source code and a win64 build. dar also supports building a statically-linked Linux binary. It would therefore be easy to include win64 binary, Linux binary, and source with every archive run. dar is also a part of multiple Linux and BSD distributions, which are archived around the Internet. I think this provides a reasonable future-proofing to make sure dar archives will still be readable in the future.
The other challenge is user ability. While dar is highly portable, it is fundamentally a CLI tool and will require CLI abilities on the part of users. I suspect, though, that I could write up a few pages of instructions to include and make that a reasonably easy process. Not everyone can use a CLI, but I would expect a person that could follow those instructions could be readily-enough found.
One other benefit of dar is that it could easily be used with tapes. The LTO series is liked by various hobbyists, though it could pose formidable obstacles to non-hobbyists trying to aceess data in future decades. Additionally, since the archive is a big file, it lends itself to working with par2 to provide redundancy for certain amounts of data corruption.
git-annex
git-annex is an interesting program that is designed to facilitate managing large sets of data and moving it between repositories. git-annex has particular support for offline archive drives and tracks which drives contain which files.
The idea would be to store the data to be archived in a git-annex repository. Then git-annex commands could generate filesystem trees on the external drives (or trees to br burned to read-only media).
In a post about using git-annex for blu-ray backups, an earlier thread about DVD-Rs was mentioned.
This has a few interesting properties. For one, with due care, the files can be stored on archival media as regular files. There are some different options for how to generate the archives; some of them would place the entire git-annex metadata on each drive/disc. With that arrangement, one could access the individual files without git-annex. With git-annex, one could reconstruct the final (or any intermediate) state of the archive appropriately, handling deltions, renames, etc. You would also easily be able to know where copies of your files are.
The practice is somewhat more challenging. Hundreds of thousands of files what I would consider a medium-sized archive can pose some challenges, running into hours-long execution if used in conjunction with the directory special remote (but only minutes-long with a standard git-annex repo).
Ruling out the directory special remote, I had thought I could maybe just work with my files in git-annex directly. However, I ran into some challenges with that approach as well. I am uncomfortable with git-annex mucking about with hard links in my source data. While it does try to preserve timestamps in the source data, these are lost on the clones. I wrote up my best effort to work around all this.
In a forum post, the author of git-annex comments that I don t think that CDs/DVDs are a particularly good fit for git-annex, but it seems a couple of users have gotten something working. The page he references is Managing a large number of files archived on many pieces of read-only medium. Some of that discussion is a bit dated (for instance, the directory special remote has the importtree feature that implements what was being asked for there), but has some interesting tips.
git-annex supplies win64 binaries, and git-annex is included with many distributions as well. So it should be nearly as accessible as dar in the future. Since git-annex would be required to restore a consistent recovery image, similar caveats as with dar apply; CLI experience would be needed, along with some written instructions.
Bacula and BareOS
Although primarily tape-based archivers, these do also also nominally support drives and optical media. However, they are much more tailored as backup tools, especially with the ability to pull from multiple machines. They require a database and extensive configuration, making them a poor fit for both the creation and future extractability of this project.
Conclusions
I m going to spend some more time with dar and git-annex, testing them out, and hope to write some future posts about my experiences.
Tobias Frost
did 15.0h (out of 15.0h assigned and 1.0h from previous period), thus carrying over 1.0h to the next month.
Utkarsh Gupta
did 3.5h (out of 11.0h assigned and 18.5h from previous period), thus carrying over 26.0h to the next month.
Evolution of the situation
In April, we have released 35 DLAs.
The LTS team would like to welcome our newest sponsor, Institut Camille Jordan, a French research lab. Thanks to the support of the many LTS sponsors, the entire Debian community benefits from direct security updates, as well as indirect improvements and collaboration with other members of the Debian community.
As part of improving the efficiency of our work and the quality of the security updates we produce, the LTS has continued improving our workflow. Improvements include more consistent tagging of release versions in Git and broader use of continuous integration (CI) to ensure packages are tested thoroughly and consistently. Sponsors and users can rest assured that we work continuously to maintain and improve the already high quality of the work that we do.
Thanks to our sponsors
Sponsors that joined recently are in bold.
India Press Freedom
Just about a week back, India again slipped in the Freedom index, this time falling to 161 out of 180 countries. The RW again made lot of noise as they cannot fathom why it has been happening so. A recent news story gives some idea. Every year NCRB (National Crime Records Bureau) puts out its statistics of crimes happening across the country. The report is in public domain. Now according to report shared, around 40k women from Gujarat alone disappeared in the last five years. This is a state where BJP has been ruling for the last 30 odd years. When this report became viral, almost all national newspapers the news was censored/blacked out. For e.g. check out newindianexpress.com, likewise TOI and other newspapers, the news has been 404. The only place that you can get that news is in minority papers like siasat. But the story didn t remain till there. While the NCW (National Commission of Women) pointed out similar stuff happening in J&K, Gujarat Police claimed they got almost 39k women back. Now ideally, it should have been in NCRB data as an addendum as the report can be challenged. But as this news was made viral, nobody knows the truth or false in the above. What BJP has been doing is whenever they get questioned, they try to muddy the waters like that. And most of the time, such news doesn t make to court so the party gets a freebie in a sort as they are not legally challenged. Even if somebody asks why didn t Gujarat Police do it as NCRB report is jointly made with the help of all states, and especially with BJP both in Center and States, they cannot give any excuse. The only excuse you see or hear is whataboutism unfortunately
Profiteering on I.T. Hardware
I was chatting with a friend yesterday who is an enthusiast like me but has been more alert about what has been happening in the CPU, motherboard, RAM world. I was simply shocked to hear the prices of motherboards which are three years old, even a middling motherboard. For e.g. the last time I bought a mobo, I spent about 6k but that was for an ATX motherboard. Most ITX motherboards usually sold for around INR 4k/- or even lower. I remember Via especially as their mobos were even cheaper around INR 1.5-2k/-. Even before pandemic, many motherboard manufacturers had closed down shop leaving only a few in the market. As only a few remained, prices started going higher. The pandemic turned it to a seller s market overnight as most people were stuck at home and needed good rigs for either work or leisure or both. The manufacturers of CPU, motherboards, GPU s, Powersupply (SMPS) named their prices and people bought it. So in 2023, high prices remained while warranty periods started coming down. Governments also upped customs and various other duties. So all are in hand in glove in the situation. So as shared before, what I have been offered is a 4 year motherboard with a CPU of that time. I haven t bought it nor do I intend to in short-term future but extremely disappointed with the state of affairs
AMD Issues
It s just been couple of hard weeks apparently for AMD. The first has been the TPM (Trusted Platform Module) issue that was shown by couple of security researchers. From what is known, apparently with $200 worth of tools and with sometime you can hack into somebody machine if you have physical access. Ironically, MS made a huge show about TPM and also made it sort of a requirement if a person wanted to have Windows 11. I remember Matthew Garett sharing about TPM and issues with Lenovo laptops. While AMD has acknowledged the issue, its response has been somewhat wishy-washy. But this is not the only issue that has been plaguing AMD. There have been reports of AMD chips literally exploding and again AMD issuing a somewhat wishy-washy response. Asus though made some changes but is it for Zen4 or only 5 parts, not known. Most people are expecting a recession in I.T. hardware this year as well as next year due to high prices. No idea if things will change, if ever
This is a bug fix and minor feature release over INN 2.7.0, and the
upgrade should be painless. You can download the new release from
ISC or
my personal INN pages. The latter also has
links to the full changelog and the other INN documentation.
As of this release, we're no longer generating hashes and signed hashes.
Instead, the release is a simple tarball and a detached GnuPG signature,
similar to my other software releases. We're also maintaining the
releases in parallel on GitHub.
For the full list of changes, see the
INN 2.7.1 NEWS file.
As always, thanks to Julien LIE for preparing this release and doing most
of the maintenance work on INN!
This post serves as a report from my attendance to Kubecon and CloudNativeCon 2023 Europe that took place in
Amsterdam in April 2023. It was my second time physically attending this conference, the first one was in
Austin, Texas (USA) in 2017. I also attended once in a virtual fashion.
The content here is mostly generated for the sake of my own recollection and learnings, and is written from
the notes I took during the event.
The very first session was the opening keynote, which reunited the whole crowd to bootstrap the event and
share the excitement about the days ahead. Some astonishing numbers were announced: there were more than
10.000 people attending, and apparently it could confidently be said that it was the largest open source
technology conference taking place in Europe in recent times.
It was also communicated that the next couple iteration of the event will be run in China in September 2023
and Paris in March 2024.
More numbers, the CNCF was hosting about 159 projects, involving 1300 maintainers and about 200.000
contributors. The cloud-native community is ever-increasing, and there seems to be a strong trend in the
industry for cloud-native technology adoption and all-things related to PaaS and IaaS.
The event program had different tracks, and in each one there was an interesting mix of low-level and higher
level talks for a variety of audience. On many occasions I found that reading the talk title alone was not
enough to know in advance if a talk was a 101 kind of thing or for experienced engineers. But unlike in
previous editions, I didn t have the feeling that the purpose of the conference was to try selling me
anything. Obviously, speakers would make sure to mention, or highlight in a subtle way, the involvement of a
given company in a given solution or piece of the ecosystem. But it was non-invasive and fair enough for me.
On a different note, I found the breakout rooms to be often small. I think there were only a couple of rooms
that could accommodate more than 500 people, which is a fairly small allowance for 10k attendees. I realized
with frustration that the more interesting talks were immediately fully booked, with people waiting in line
some 45 minutes before the session time. Because of this, I missed a few important sessions that I ll
hopefully watch online later.
Finally, on a more technical side, I ve learned many things, that instead of grouping by session I ll group
by topic, given how some subjects were mentioned in several talks.
On gitops and CI/CD pipelines
Most of the mentions went to FluxCD and ArgoCD. At
that point there were no doubts that gitops was a mature approach and both flux and argoCD could do an
excellent job. ArgoCD seemed a bit more over-engineered to be a more general purpose CD pipeline, and flux
felt a bit more tailored for simpler gitops setups. I discovered that both have nice web user interfaces that
I wasn t previously familiar with.
However, in two different talks I got the impression that the initial setup of them was simple, but migrating
your current workflow to gitops could result in a bumpy ride. This is, the challenge is not deploying
flux/argo itself, but moving everything into a state that both humans and flux/argo can understand. I also
saw some curious mentions to the config drifts that can happen in some cases, even if the goal of gitops is
precisely for that to never happen. Such mentions were usually accompanied by some hints on how to operate
the situation by hand.
Worth mentioning, I missed any practical information about one of the key pieces to this whole gitops story:
building container images. Most of the showcased scenarios were using pre-built container images, so in that
sense they were simple. Building and pushing to an image registry is one of the two key points we would need
to solve in Toolforge Kubernetes if adopting gitops.
In general, even if gitops were already in our radar for
Toolforge Kubernetes,
I think it climbed a few steps in my priority list after the conference.
Another learning was this site: https://opengitops.dev/.
On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the exactsameproblems we
have had in Toolforge Kubernetes, like api-server and etcd failure modes, and how sensitive etcd is to disk
latency, IO pressure and network throughput. Even though
Toolforge Kubernetes scale is small compared to other Kubernetes deployments out there, I found it very
interesting to see other s approaches to the same set of challenges.
I learned how most Kubernetes components and apps can overload the api-server. Because even the api-server
talks to itself. Simple things like kubectl may have a completely different impact on the API depending on
usage, for example when listing the whole list of objects (very expensive) vs a single object.
The conclusion was to try avoiding hitting the api-server with LIST calls, and use ResourceVersion which
avoids full-dumps from etcd (which, by the way, is the default when using bare kubectl get calls). I
already knew some of this, and for example the jobs-framework-emailer was already making use of this
ResourceVersion functionality.
There have been a lot of improvements in the performance side of Kubernetes in recent times, or more
specifically, in how resources are managed and used by the system. I saw a review of resource management from
the perspective of the container runtime and kubelet, and plans to support fancy things like topology-aware
scheduling decisions and dynamic resource claims (changing the pod resource claims without
re-defining/re-starting the pods).
On cluster management, bootstrapping and multi-tenancy
I attended a couple of talks that mentioned kubeadm, and one in particular was from the maintainers
themselves. This was of interest to me because as of today we use it for
Toolforge. They shared all
the latest developments and improvements, and the plans and roadmap for the future, with a special mention to
something they called kubeadm operator , apparently capable of auto-upgrading the cluster, auto-renewing
certificates and such.
I also saw a comparison between the different cluster bootstrappers, which to me confirmed that kubeadm was
the best, from the point of view of being a well established and well-known workflow, plus having a very
active contributor base. The kubeadm developers invited the audience to submit feature requests,
so I did.
The different talks confirmed that the basic unit for multi-tenancy in kubernetes is the namespace. Any
serious multi-tenant usage should leverage this. There were some ongoing conversations, in official sessions
and in the hallway, about the right tool to implement K8s-whitin-K8s, and vcluster
was mentioned enough times for me to be convinced it was the right candidate. This was despite of my impression
that multiclusters / multicloud are regarded as hard topics in the general community. I definitely would like to play
with it sometime down the road.
On networking
I attended a couple of basic sessions that served really well to understand how Kubernetes instrumented the
network to achieve its goal. The conference program had sessions to cover topics ranging from network
debugging recommendations, CNI implementations, to IPv6 support. Also, one of the keynote sessions had a
reference to how kube-proxy is not able to perform NAT for SIP connections, which is interesting because I
believe Netfilter Conntrack could do it if properly configured. One of the conclusions on the CNI front was
that Calico has a massive community adoption (in Netfilter mode), which is reassuring, especially considering
it is the one we use for Toolforge Kubernetes.
On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in Toolforge Jobs Framework?
On policy and security
A surprisingly good amount of sessions covered interesting topics related to policy and security. It was nice
to learn two realities:
kubernetes is capable of doing pretty much anything security-wise and create
greatly secured environments.
it does not by default. The defaults are not security-strict on purpose.
It kind of made sense to me: Kubernetes was used for a wide range of use cases, and developers didn t know
beforehand to which particular setup they should accommodate the default security levels.
One session in particular covered the most basic security features that should be enabled for any Kubernetes
system that would get exposed to random end users. In my opinion, the Toolforge Kubernetes setup was already
doing a good job in that regard. To my joy, some sessions referred to the Pod Security Admission mechanism,
which is one of the key security features we re about to adopt (when migrating away from
Pod Security Policy).
I also learned a bit more about Secret resources, their current implementation and how to leverage a
combo of CSI and RBAC for a more secure usage of external secrets.
Finally, one of the major takeaways from the conference was learning about kyverno and
kubeaudit. I was previously aware of the
OPA Gatekeeper. From the several demos I saw, it
was to me that kyverno should help us make Toolforge Kubernetes more sustainable by replacing all of our
custom admission controllers
with it. I already opened a ticket to track this idea, which I ll be
proposing to my team soon.
Final notes
In general, I believe I learned many things, and perhaps even more importantly I re-learned some stuff I had
forgotten because of lack of daily exposure. I m really happy that the cloud native way of thinking was
reinforced in me, which I still need because most of my muscle memory to approach systems architecture and
engineering is from the old pre-cloud days.
List of sessions I attended on the first day:
Babel, or the Necessity of Violence: An Arcane History of the Oxford
Translators' Revolution, to give it its full title, is a standalone
dark academia fantasy
set in the 1830s and 1840s, primarily in Oxford, England. The first book
of R.F. Kuang's previous trilogy, The Poppy War, was nominated for
multiple awards and won the Compton Crook Award for best first novel.
Babel is her fourth book.
Robin Swift, although that was not his name at the time, was born and
raised in Canton and educated by an inexplicable English tutor his family
could not have afforded. After his entire family dies of cholera, he is
plucked from China by a British professor and offered a life in England as
his ward. What follows is a paradise of books, a hell of relentless and
demanding instruction, and an unpredictably abusive emotional environment,
all aiming him towards admission to Oxford University. Robin will join
University College and the Royal Institute of Translation.
The politics of this imperial Britain are almost precisely the same as in
our history, but one of the engines is profoundly different. This world
has magic. If words from two different languages are engraved on a metal
bar (silver is best), the meaning and nuance lost in translation becomes
magical power. With a careful choice of translation pairs, and sometimes
additional help from other related words and techniques, the silver bar
becomes a persistent spell. Britain's industrial revolution is in
overdrive thanks to the country's vast stores of silver and the applied
translation prowess of Babel.
This means Babel is also the only part of very racist Oxford that accepts
non-white students and women. They need translators (barely) more than
they care about maintaining social hierarchy; translation pairs only work
when the translator is fluent in both languages. The magic is also
stronger when meanings are more distinct, which is creating serious
worries about classical and European languages. Those are still the bulk
of Babel's work, but increased trade and communication within Europe is
eroding the meaning distinctions and thus the amount of magical power.
More remote languages, such as Chinese and Urdu, are full of untapped
promise that Britain's colonial empire wants to capture. Professor
Lowell, Robin's dubious benefactor, is a specialist in Chinese languages;
Robin is a potential tool for his plans.
As Robin discovers shortly after arriving in Oxford, he is not the first
of Lowell's tools. His predecessor turned against Babel and is trying to
break its chokehold on translation magic. He wants Robin to help.
This is one of those books that is hard to review because it does some
things exceptionally well and other things that did not work for me. It's
not obvious if the latter are flaws in the book or a mismatch between book
and reader (or, frankly, flaws in the reader). I'll try to explain as
best I can so that you can draw your own conclusions.
First, this is one of the all-time great magical system hooks. The way
words are tapped for power is fully fleshed out and exceptionally
well-done. Kuang is a professional translator, which shows in the
attention to detail on translation pairs. I think this is the
best-constructed and explained word-based magic system I've read in
fantasy. Many word-based systems treat magic as its own separate language
that is weirdly universal. Here, Kuang does the exact opposite, and the
result is immensely satisfying.
A fantasy reader may expect exploration of this magic system to be the
primary point of the book, however, and this is not the case. It is an
important part of the book, and its implications are essential to the plot
resolution, but this is not the type of fantasy novel where the plot is
driven by character exploration of the magic system. The magic system
exists, the characters use it, and we do get some crunchy details, but the
heart of the book is elsewhere. If you were expecting the typical
relationship of a fantasy novel to its magic system, you may get a bit
wrong-footed.
Similarly, this is historical fantasy, but it is the type of historical
fantasy where the existence of magic causes no significant differences.
For some people, this is a pet peeve; personally, I don't mind that choice
in the abstract, but some of the specifics bugged me.
The villains of this book assert that any country could have done what
Britain did in developing translation magic, and thus their hoarding of it
is not immoral. They are obviously partly lying (this is a classic
justification for imperialism), but it's not clear from the book how they
are lying. Technologies (and magic here works like a technology) tend to
concentrate power when they require significant capital investment, and
tend to dilute power when they are portable and easy to teach.
Translation magic feels like the latter, but its effect in the book is
clearly the former, and I was never sure why.
England is not an obvious choice to be a translation superpower. Yes,
it's a colonial empire, but India, southeast Asia, and most certainly
Africa (the continent largely not appearing in this book) are home to
considerably more languages from more wildly disparate families than
western Europe. Translation is not a peculiarly European idea, and this
magic system does not seem hard to stumble across. It's not clear why
England, and Oxford in particular, is so dramatically far ahead. There is
some sign that Babel is keeping the mechanics of translation magic secret,
but that secret has leaked, seems easy to develop independently, and is
simple enough that a new student can perform basic magic with a few hours
of instruction. This does not feel like the kind of power that would be
easy to concentrate, let alone to the extreme extent required by the last
quarter of this book.
The demand for silver as a base material for translation magic provides a
justification for mercantilism that avoids the confusing complexities of
currency economics in our actual history, so fine, I guess, but it was a
bit disappointing for this great of an idea for a magic system to have
this small of an impact on politics.
I'll come to the actual thrust of this book in a moment, but first
something else Babel does exceptionally well: dark academia.
The remainder of Robin's cohort at Oxford is Remy, a dark-skinned Muslim
from Calcutta; Victoire, a Haitian woman raised in France; and Letty, the
daughter of a British admiral. All of them are non-white except Letty,
and Letty and Victoire additionally have to deal with the blatant sexism
of the time. (For example, they have to live several miles from Oxford
because women living near the college would be a "distraction.")
The interpersonal dynamics between the four are exceptionally well done.
Kuang captures the dislocation of going away to college, the unsettled
life upheaval that makes it both easy and vital to form suddenly tight
friendships, and the way that the immense pressure from classes and exams
leaves one so devoid of spare emotional capacity that those friendships
become both unbreakable and badly strained. Robin and Remy almost
immediately become inseparable in that type of college friendship in which
profound trust and constant companionship happen first and learning about
the other person happens afterwards.
It's tricky to talk about this without spoilers, but one of the things
Kuang sets up with this friend group is a pointed look at
intersectionality. Babel has gotten a lot of positive review buzz,
and I think this is one of the reasons why. Kuang does not pass over or
make excuses for characters in a place where many other books do. This
mostly worked for me, but with a substantial caveat that I think you may
want to be aware of before you dive into this book.
Babel is set in the 1830s, but it is very much about the politics
of 2022. That does not necessarily mean that the politics are off for the
1830s; I haven't done the research to know, and it's possible I'm seeing
the Tiffany problem (Jo Walton's observation that Tiffany is a historical
12th century women's name, but an author can't use it as a medieval name
because readers think it sounds too modern). But I found it hard to shake
the feeling that the characters make sense of their world using modern
analytical frameworks of imperialism, racism, sexism, and intersectional
feminism, although without using modern terminology, and characters from
the 1830s would react somewhat differently. This is a valid authorial
choice; all books are written for the readers of the time when they're
published. But as with magical systems that don't change history, it's a
pet peeve for some readers. If that's you, be aware that's the feel I got
from it.
The true center of this book is not the magic system or the history. It's
advertised directly in the title the necessity of violence although
it's not until well into the book before the reader knows what that means.
This is a book about revolution, what revolution means, what decisions you
have to make along the way, how the personal affects the political, and
the inadequacy of reform politics. It is hard, uncomfortable, and not
gentle on its characters.
The last quarter of this book was exceptional, and I understand why it's
getting so much attention. Kuang directly confronts the desire for
someone else to do the necessary work, the hope that surely the people
with power will see reason, and the feeling of despair when there are no
good plans and every reason to wait and do nothing when atrocities are
about to happen. If you are familiar with radical politics, these aren't
new questions, but this is not the sort of thing that normally shows up in
fantasy. It does not surprise me that Babel struck a nerve with
readers a generation or two younger than me. It captures that heady
feeling on the cusp of adulthood when everything is in flux and one is
assembling an independent politics for the first time. Once I neared the
end of the book, I could not put it down. The ending is brutal, but I
think it was the right ending for this book.
There are two things, though, that I did not like about the political arc.
The first is that Victoire is a much more interesting character than
Robin, but is sidelined for most of the book. The difference of
perspectives between her and Robin is the heart of what makes the end of
this book so good, and I wish that had started 300 pages earlier. Or,
even better, I wish Victoire has been the protagonist; I liked Robin, but
he's a very predictable character for most of the book. Victoire is not;
even the conflicts she had earlier in the book, when she didn't get much
attention in the story, felt more dynamic and more thoughtful than Robin's
mix of guilt and anxiety.
The second is that I wish Kuang had shown more of Robin's intellectual
evolution. All of the pieces of why he makes the decisions that he does
are present in this book, and Kuang shows his emotional state (sometimes
in agonizing detail) at each step, but the sense-making, the development
of theory and ideology beneath the actions, is hinted at but not shown.
This is a stylistic choice with no one right answer, but it felt odd
because so much of the rest of the plot is obvious and telegraphed. If
the reader shares Robin's perspective, I think it's easy to fill in the
gaps, but it felt odd to read Robin giving clearly thought-out political
analyses at the end of the book without seeing the hashing-out and
argument with friends required to develop those analyses. I felt like I
had to do a lot of heavy lifting as the reader, work that I wish had been
done directly by the book.
My final note about this book is that I found much of it extremely
predictable. I think that's part of why reviewers describe it as
accessible and easy to read; accessibility and predictability can be two
sides of the same coin. Kuang did not intend for this book to be subtle,
and I think that's part of the appeal. But very few of Robin's actions
for the first three-quarters of the book surprised me, and that's not
always the reading experience I want. The end of the book is different,
and I therefore found it much more gripping, but it takes a while to get
there.
Babel is, for better or worse, the type of fantasy where the
politics, economics, and magic system exist primarily to justify the plot
the author wanted. I don't think the societal position of the Institute
of Translation that makes the ending possible is that believable given the
nature of the technology in question and the politics of the time, and if
you are inclined to dig into the specifics of the world-building, I think
you will find it frustrating. Where it succeeds brilliantly is in
capturing the social dynamics of hothouse academic cohorts, and in making
a sharp and unfortunately timely argument about the role of violence in
political change, in a way that the traditionally conservative setting of
fantasy rarely does.
I can't say Babel blew me away, but I can see why others liked it
so much. If I had to guess, I'd say that the closer one is in age to the
characters in the book and to that moment of political identity
construction, the more it's likely to appeal.
Rating: 7 out of 10
 I very, very nearly didn t make it to DebConf this year, I had a bad cold/flu for a few days before I left, and after a negative covid-19 test just minutes before my flight, I decided to take the plunge and travel.
This is just everything in chronological order, more or less, it s the only way I could write it.
I very, very nearly didn t make it to DebConf this year, I had a bad cold/flu for a few days before I left, and after a negative covid-19 test just minutes before my flight, I decided to take the plunge and travel.
This is just everything in chronological order, more or less, it s the only way I could write it.











 If you got one of these Cheese & Wine bags from DebConf, that s from the South African local group!
If you got one of these Cheese & Wine bags from DebConf, that s from the South African local group! Some hopefully harmless soldering.
Some hopefully harmless soldering.



 This post describes how to handle files that are used as assets by jobs and pipelines defined on a common gitlab-ci
repository when we include those definitions from a different project.
This post describes how to handle files that are used as assets by jobs and pipelines defined on a common gitlab-ci
repository when we include those definitions from a different project.

 QNAP TS-453mini product photo
QNAP TS-453mini product photo The logo for QNAP HappyGet 2 and Blizzard s StarCraft 2 side by side
The logo for QNAP HappyGet 2 and Blizzard s StarCraft 2 side by side Thermalright AXP120-X67, AMD Ryzen 5 PRO 5650GE, ASRock Rack X570D4I-2T, all assembled and running on a flat surface
Thermalright AXP120-X67, AMD Ryzen 5 PRO 5650GE, ASRock Rack X570D4I-2T, all assembled and running on a flat surface Memtest86 showing test progress, taken from IPMI remote control window
Memtest86 showing test progress, taken from IPMI remote control window Screenshot of PCIe 16x slot bifurcation options in UEFI settings, taken from IPMI remote control window
Screenshot of PCIe 16x slot bifurcation options in UEFI settings, taken from IPMI remote control window Internal image of Silverstone CS280 NAS build. Image stolen from
Internal image of Silverstone CS280 NAS build. Image stolen from  Internal image of Silverstone CS280 NAS build. Image stolen from
Internal image of Silverstone CS280 NAS build. Image stolen from  NAS build in Silverstone SUGO 14, mid build, panels removed
NAS build in Silverstone SUGO 14, mid build, panels removed Silverstone SUGO 14 from the front, with hot swap bay installed
Silverstone SUGO 14 from the front, with hot swap bay installed Storage SSD loaded into hot swap sled
Storage SSD loaded into hot swap sled TrueNAS Dashboard screenshot in browser window
TrueNAS Dashboard screenshot in browser window The final system, powered up
The final system, powered up
 September.
Looking at performance traces and analysing scheduling and other issues.
CPU Cache doesn't really play into effect until I figure out the scheduling issues. They don't collide.
September.
Looking at performance traces and analysing scheduling and other issues.
CPU Cache doesn't really play into effect until I figure out the scheduling issues. They don't collide.

 . Internet shutdowns impact women
. Internet shutdowns impact women 
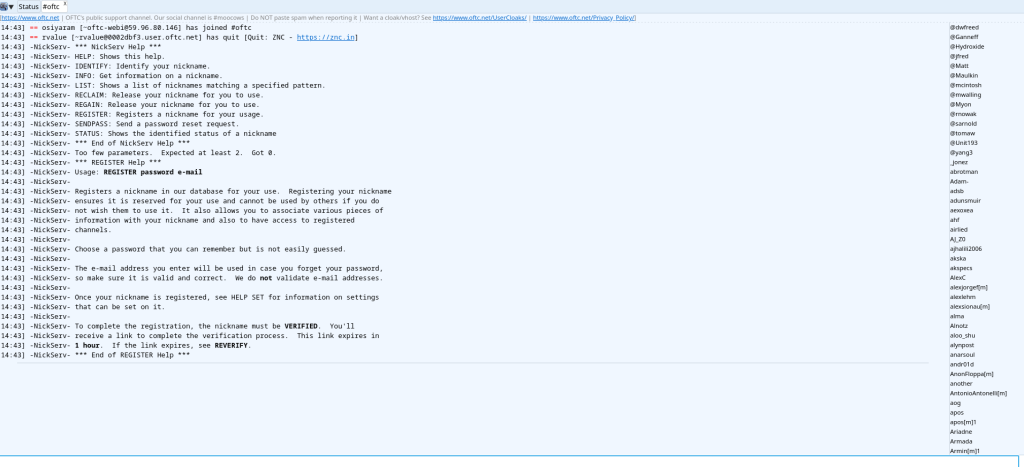
 About 6 months ago, I decided to purchase a bike trailer. I don't drive and
although I also have a shopping caddy, it often can't handle a week's
groceries.
About 6 months ago, I decided to purchase a bike trailer. I don't drive and
although I also have a shopping caddy, it often can't handle a week's
groceries.
 Since the goal for the trailer was to haul encumbering and heavy loads, I
decided to splurge and got a
Since the goal for the trailer was to haul encumbering and heavy loads, I
decided to splurge and got a  So far, I've used the trailer to go grocery shopping, buy bulk food and haul
dirt and mulch. To make things easier, I've purchased two
So far, I've used the trailer to go grocery shopping, buy bulk food and haul
dirt and mulch. To make things easier, I've purchased two  Although my housing cooperative has a (small) indoor bicycle parking space, my
partner uses our spot during the summer, which means I have to store the
trailer on my balcony. To make things more manageable and free up some space, I
set up a system of pulleys to hoist the trailer up the air when it's not in
use.
I did go through a few iterations, but I'm pretty happy with the current 8
pulleys block and tackle mechanism I rigged.
Although my housing cooperative has a (small) indoor bicycle parking space, my
partner uses our spot during the summer, which means I have to store the
trailer on my balcony. To make things more manageable and free up some space, I
set up a system of pulleys to hoist the trailer up the air when it's not in
use.
I did go through a few iterations, but I'm pretty happy with the current 8
pulleys block and tackle mechanism I rigged.
 All and all, this trailer wasn't cheap, but I regret nothing. Knowing Surley's
reputation, it will last me many years and not having to drive a car to get
around always ends up being the cheaper solution.
All and all, this trailer wasn't cheap, but I regret nothing. Knowing Surley's
reputation, it will last me many years and not having to drive a car to get
around always ends up being the cheaper solution.
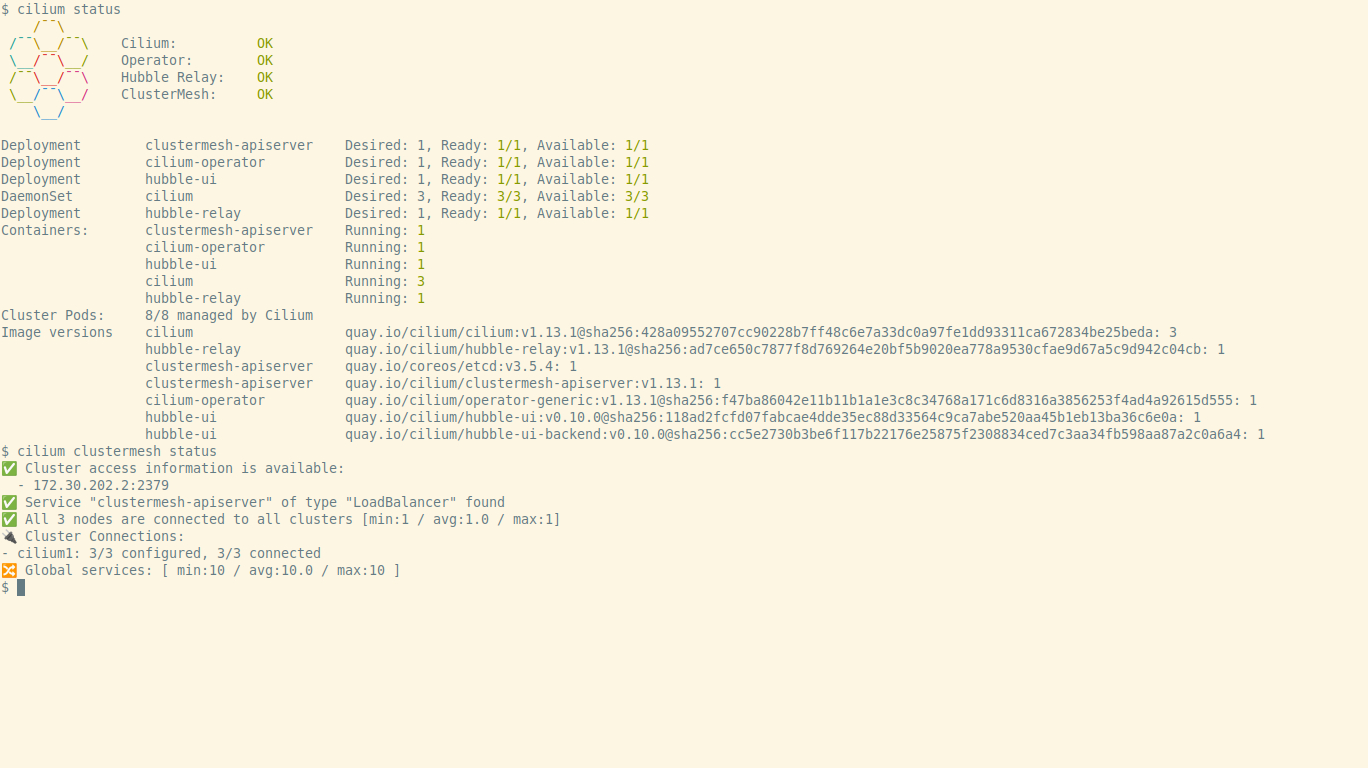
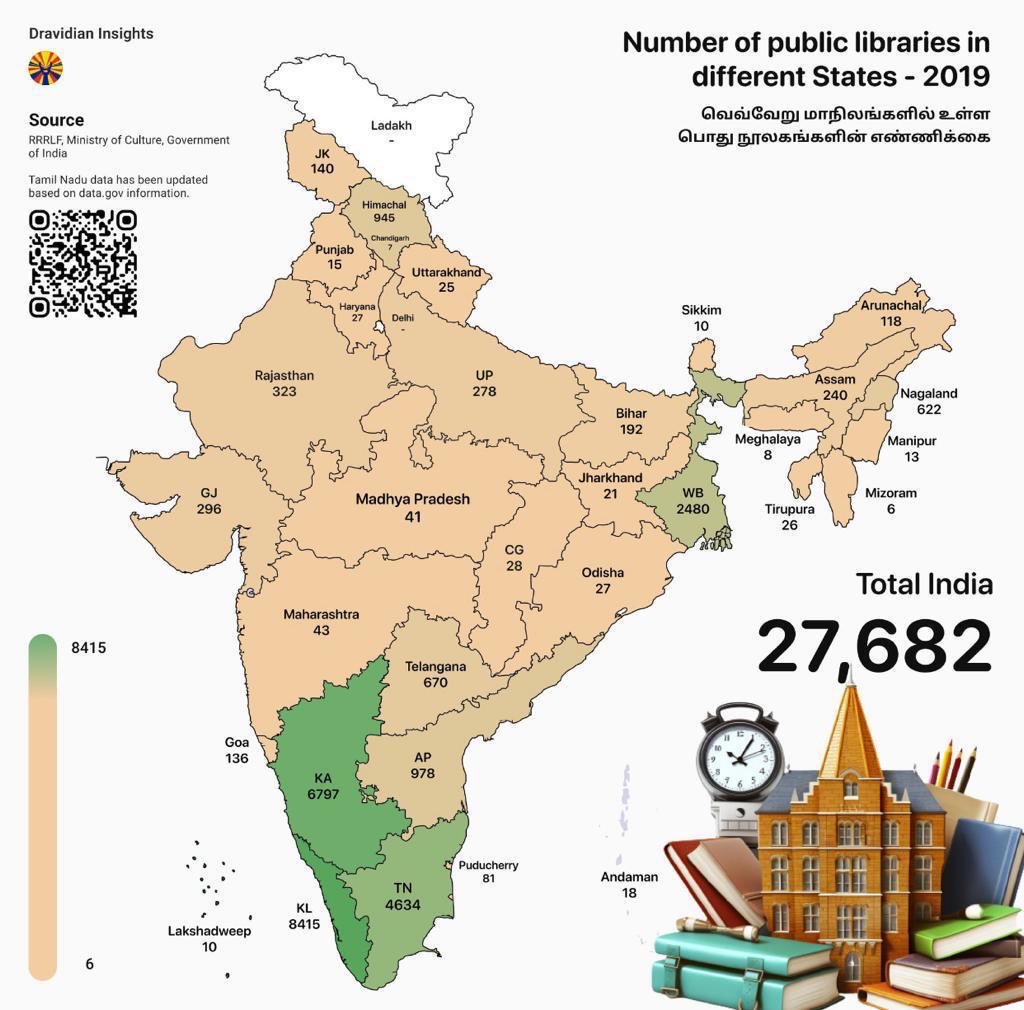
 I have had the pleasure to have Poha in many ways. One of my favorite ones is when people have actually put tadka on top of Poha. You do everything else but in a slight reverse order. The tadka has all the spices mixed and is concentrated and is put on top of Poha and then mixed. Done right, it tastes out of this world. For those who might not have had the Indian culinary experience, most of which is actually borrowed from the Mughals, you are in for a treat.
One of the other things I would suggest to people is to ask people where there can get five types of rice. This is a specialty of South India and a sort of street food. I know where you can get it Hyderabad, Bangalore, Chennai but not in Kerala, although am dead sure there is, just somehow have missed it. If asked, am sure the Kerala team should be able to guide.
That s all for now, feeling hungry, having dinner as have been sharing about cooking.
I have had the pleasure to have Poha in many ways. One of my favorite ones is when people have actually put tadka on top of Poha. You do everything else but in a slight reverse order. The tadka has all the spices mixed and is concentrated and is put on top of Poha and then mixed. Done right, it tastes out of this world. For those who might not have had the Indian culinary experience, most of which is actually borrowed from the Mughals, you are in for a treat.
One of the other things I would suggest to people is to ask people where there can get five types of rice. This is a specialty of South India and a sort of street food. I know where you can get it Hyderabad, Bangalore, Chennai but not in Kerala, although am dead sure there is, just somehow have missed it. If asked, am sure the Kerala team should be able to guide.
That s all for now, feeling hungry, having dinner as have been sharing about cooking.


 On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the
On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the  On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in
On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in